복습)
declare
type rec_type is record(a varchar2(30), b date, c varchar2(30), d varchar2(30));
type tab_type is table of rec_type index by pls_integer;
v_tab tab_type;
type id_type is table of number index by pls_integer;
v_id id_type;
begin
v_id(1):= 100;
v_id(2) := 155;
v_id(3) := 201;
for i in v_id.first..v_id.last loop
select e.first_name, e.hire_date, d.department_name, l.city
into v_tab(i)
from hr.employees e, hr.departments d, hr.locations l
where e.department_id = d.department_id
and d.location_id = l.location_id
and e.employee_id = v_id(i);
end loop;
for i in v_tab.first..v_tab.last loop
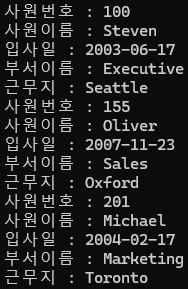
dbms_output.put_line('사원번호 : '||v_id(i));
dbms_output.put_line('사원이름 : '||v_tab(i).a);
dbms_output.put_line('입사일 : '||to_char(v_tab(i).b, 'yyyy-mm-dd'));
dbms_output.put_line('부서이름 : '||v_tab(i).c);
dbms_output.put_line('근무지 : '||v_tab(i).d);
end loop;
end;
/
▶ 레코드 선언해도 되고, 배열을 만들어서 해도 된다. (선택)
▶ 레코드 타입을 생성해서 변수를 선언해 주고, 그 속성을 참조해서 1차원 배열을 만든다.
▶ first_name, hire_date, department_name, city을 값을 넣어줄 때 데이터를 쌓아놓기 위한 v_id라는 배열을 만들어준다.
# 값을 알 경우 중첩테이블을 이용해 가독성을 높히는 게 좋다.
declare
type rec_type is record(a varchar2(30), b date, c varchar2(30), d varchar2(30));
type tab_type is table of rec_type index by pls_integer;
v_tab tab_type;
type id_type is table of number;
v_id id_type := id_type(100,155,201);
begin
for i in v_id.first..v_id.last loop
select e.first_name, e.hire_date, d.department_name, l.city
into v_tab(i)
from hr.employees e, hr.departments d, hr.locations l
where e.department_id = d.department_id
and d.location_id = l.location_id
and e.employee_id = v_id(i);
end loop;
for i in v_tab.first..v_tab.last loop
dbms_output.put_line('사원번호 : '||v_id(i));
dbms_output.put_line('사원이름 : '||v_tab(i).a);
dbms_output.put_line('입사일 : '||to_char(v_tab(i).b, 'yyyy-mm-dd'));
dbms_output.put_line('부서이름 : '||v_tab(i).c);
dbms_output.put_line('근무지 : '||v_tab(i).d);
end loop;
end;
/▶ 중첩테이블을 이용해서 좀 더 간편하게 만들 순 있지만 대신 2GB까지 이용 가능하다.
▶ index by는 4GB까지 가능 (-2GB ~ 2GB)
# 선언해주고 싶을 경우
declare
type rec_type is record(a varchar2(30), b date, c varchar2(30), d varchar2(30));
type tab_type is table of rec_type index by pls_integer;
v_tab tab_type;
type id_type is table of number;
v_id id_type;
begin
v_id := id_type(100,155,201);
for i in v_id.first..v_id.last loop
select e.first_name, e.hire_date, d.department_name, l.city
into v_tab(i)
from hr.employees e, hr.departments d, hr.locations l
where e.department_id = d.department_id
and d.location_id = l.location_id
and e.employee_id = v_id(i);
end loop;
for i in v_tab.first..v_tab.last loop
dbms_output.put_line('사원번호 : '||v_id(i));
dbms_output.put_line('사원이름 : '||v_tab(i).a);
dbms_output.put_line('입사일 : '||to_char(v_tab(i).b, 'yyyy-mm-dd'));
dbms_output.put_line('부서이름 : '||v_tab(i).c);
dbms_output.put_line('근무지 : '||v_tab(i).d);
end loop;
end;
/▶ 선언 시 입력해야할 값을 나열해도 되지만 begin절에 입력해도 같은 결과가 나온다.
▶ 하지만 그 밑에 ex) v_id(1) := 100 쓰면 오류 뜬다.
# 값을 추가하고 싶을 경우
declare
type rec_type is record(a varchar2(30), b date, c varchar2(30), d varchar2(30));
type tab_type is table of rec_type index by pls_integer;
v_tab tab_type;
type id_type is table of number;
v_id id_type;
begin
v_id := id_type(100,155,201);
v_id.extend(1);
v_id(4) := 200;
for i in v_id.first..v_id.last loop
select e.first_name, e.hire_date, d.department_name, l.city
into v_tab(i)
from hr.employees e, hr.departments d, hr.locations l
where e.department_id = d.department_id
and d.location_id = l.location_id
and e.employee_id = v_id(i);
end loop;
for i in v_tab.first..v_tab.last loop
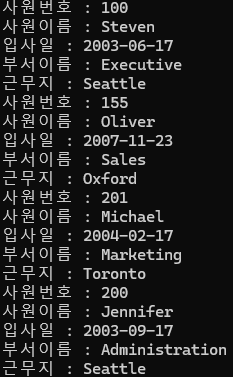
dbms_output.put_line('사원번호 : '||v_id(i));
dbms_output.put_line('사원이름 : '||v_tab(i).a);
dbms_output.put_line('입사일 : '||to_char(v_tab(i).b, 'yyyy-mm-dd'));
dbms_output.put_line('부서이름 : '||v_tab(i).c);
dbms_output.put_line('근무지 : '||v_tab(i).d);
end loop;
end;
/
▶ 값을 추가해서 넣고 싶을 경우 v_extend(추가할 값 개수)를 이용해서 데이터를 추가할 수 있다.
■ VARRAY (Variable Size Array) - 가변길이 배열
- 고정된 상한값이 있다. 선언 시 상한값을 지정해야 한다.
- 최대 크기는 2GB
- varray(n) : 상한값을 n만큼 제한하겠다. 만약에 n보다 적은 데이터가 입력이 되어도 비어있는 공간은 본인이 다 갖고 있기 때문에 extend를 사용해도 에러가 발생한다.
- varray에서는 delete 메서드를 사용할 수 없다. (어느 위치에 값을 삭제하고 싶을 경우엔 varray를 사용하면 안 된다.)
- trim 메소드를 이용해서 제일 뒤에 몇 개를 삭제할 수 있다. trim메소드를 사용하고 데이터를 추가하면 에러가 발생하지만 중간에 extend메서드를 이용하면 데이터가 추가된다.
ex)
declare
type char_type is varray(3) of varchar2(10);
v_city char_type := char_type('서울', '대구', '부산');
begin
for i in v_city.first..v_city.last loop
dbms_output.put_line(v_city(i));
end loop;
end;
/
# 값을 추가할 경우
declare
type char_type is varray(3) of varchar2(10);
v_city char_type := char_type('서울', '대구', '부산');
begin
v_city(4) := '제주';
for i in v_city.first..v_city.last loop
dbms_output.put_line(v_city(i));
end loop;
end;
/declare
type char_type is varray(3) of varchar2(10);
v_city char_type := char_type('서울', '대구', '부산');
begin
v_city.extend(1);
v_city(4) := '제주';
for i in v_city.first..v_city.last loop
dbms_output.put_line(v_city(i));
end loop;
end;
/
▶ array의 범위를 오바했다고 오류가 발생한다. (상한값의 오버가 되면 안 된다.)
▶ extend를 이용해서 동일한 오류가 발생한다.
ex) 값을 추가하고 싶을 경우
declare
type char_type is varray(4) of varchar2(10);
v_city char_type := char_type('서울', '대구', '부산');
begin
v_city.extend(1);
v_city(4) := '제주';
for i in v_city.first..v_city.last loop
dbms_output.put_line(v_city(i));
end loop;
end;
/
▶ varray 상한값을 늘려주고, extend를 써줘야 실행이 된다.
ex)
declare
type char_type is varray(3) of varchar2(10);
v_city char_type := char_type('서울', '대구', '부산');
begin
v_city.delete(3);
v_city(4) := '제주';
for i in v_city.first..v_city.last loop
dbms_output.put_line(v_city(i));
end loop;
end;
/
▶delete 사용할 경우 에러 발생한다.
ex)
declare
type char_type is varray(3) of varchar2(10);
v_city char_type := char_type('서울', '대구', '부산');
begin
v_city.trim(1);
for i in v_city.first..v_city.last loop
dbms_output.put_line(v_city(i));
end loop;
end;
/
▶ trim(1)을 통해 가장 뒤에 있는 첫 번째 값을 삭제하는 의미이기 때문에 '부산'을 삭제하고 출력이 된 것이다.
ex)
declare
type char_type is varray(3) of varchar2(10);
v_city char_type := char_type('서울', '대구', '부산');
begin
v_city(3) := '제주';
for i in v_city.first..v_city.last loop
dbms_output.put_line(v_city(i));
end loop;
end;
/
▶ 변경할 땐 아무 문제 없이 변경할 수 있다.
■ cursor : SQL문 실행 메모리 영역
- SELECT문 (무조건 1건만 fetch)
1) parse
2) bind
3) execute
4) fetch (select into절 필수)
- DML문
1) parse
2) bind
3) execute
■ 명시적 커서 (Explicit Cursor)
- SELECT 수행 시 여러 개의 행(row)을 FETCH 해야한다면 꼭 명시적 커서를 이용해야 한다.
- 프로그래머가 cursor를 생성 관리해야 한다.
- 순서 (매뉴얼 하게 해야 한다.)
1. CURSOR 선언 : 이름이 있는 SQL영역 선언
2. CURSOR OPEN : BEGIN절에서 OPEN, CURSOR 이름으로 메모리가 할당된다. (PARSE, BIND, EXECUTE 실행)
3. FETCH : CURSOR에 있는 ACTIVE SET(결과집합이라고 생각하면 된다.)을 변수에 로드하는 단계
4. CLOSE : 커서를 해제한다. 메모리 해제
ex)
declare
/* 1. cursor 선언 (선언 시엔 메모리에 할당되지 않는다.) */
CURSOR emp_cur IS
select last_name
from hr.employees
where department_id = 20;
v_name varchar2(30);
begin
/* 2. cursor를 open해야한다. */
OPEN emp_cur;
/* 3. FETCH : declare절에 변수 선언(v_name), 커서이름 꼭 써주기*/
FETCH emp_cur INTO v_name;
dbms_output.put_line(v_name);
FETCH emp_cur INTO v_name;
dbms_output.put_line(v_name);
/* 4. CLOSE */
CLOSE emp_cur;
end;
/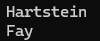
▶ FETCH는 한 건씩밖에 출력이 안 되기 때문에 또 출력하고 싶을 때는 ACTIVE SET 결과만큼 FETCH절을 또 써서 출력해야 한다.
▶ 단계를 꼭 맞춰서 해주기!
ex) ACTIVE SET 결과가 몇 개인지 모를 경우
declare
CURSOR emp_cur IS
select last_name
from hr.employees
where department_id = 20;
v_name varchar2(30);
begin
OPEN emp_cur;
loop
FETCH emp_cur INTO v_name;
exit when emp_cur%notfound;
dbms_output.put_line(v_name);
end loop;
CLOSE emp_cur;
end;
/
■ 명시적 커서 속성
- 커서이름%NOTFOUND : FETCH가 행을 반환하지 않으면 TRUE, 반환한 행이 있으면 FALSE
- 커서이름%FOUND : FETCH가 행을 반환하면 TRUE, 반환한 행이 없으면 FALSE
- 커서이름%ROWCOUNT : 지금까지 FETCH한 행의 수를 리턴한다.
- 커서이름%ISOPEN : CURSOR가 OPEN 되어있으면 TRUE, CLOSE 되어있으면 FALSE
ex)
declare
CURSOR emp_cur IS
select last_name
from hr.employees
where department_id = 20;
v_name varchar2(30);
begin
OPEN emp_cur;
loop
FETCH emp_cur INTO v_name;
exit when emp_cur%notfound;
dbms_output.put_line(v_name);
end loop;
dbms_output.put_line(emp_cur%rowcount);
CLOSE emp_cur;
end;
/
▶ FETCH를 몇 건했는지 알고 싶을 땐 %rowcount를 써주면 된다.
ex)
declare
CURSOR emp_cur IS
select last_name
from hr.employees
where department_id = 20;
v_name varchar2(30);
begin
--OPEN emp_cur; --주석처리
loop
FETCH emp_cur INTO v_name;
exit when emp_cur%notfound;
dbms_output.put_line(v_name);
end loop;
dbms_output.put_line(emp_cur%rowcount);
CLOSE emp_cur;
end;
/
▶ CURSOR가 OPEN 되어있지 않기 때문에 에러가 발생한다.
ex) 스칼라 타입으로 할 경우
declare
CURSOR emp_cur IS
select e.employee_id, e.salary, d.department_name
from hr.employees e, hr.departments d
where e.department_id = 20
and d.department_id = 20;
/* 스칼라 타입 할 경우 */
v_id number;
v_sal number;
v_name varchar2(30);
begin
OPEN emp_cur;
loop
FETCH emp_cur INTO v_id, v_sal, v_name;
exit when emp_cur%notfound;
dbms_output.put_line(v_id);
dbms_output.put_line(v_sal);
dbms_output.put_line(v_name);
end loop;
dbms_output.put_line(emp_cur%rowcount);
CLOSE emp_cur;
end;
/▶ 스칼라 타입으로 할 경우 FETCH절에 출력하는 컬럼을 다 적어줘야 한다.
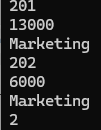
▶ 선언 시엔 SELECT에 컬럼의 수만큼 FETCH시에 INTO절에 사용을 해야 되니 꼭 선언을 타입에 맞게 선언을 해야 한다.
ex) RECORD 변수로 선언해서 사용하고 싶을 경우
declare
CURSOR emp_cur IS
select e.employee_id, e.salary, d.department_name
from hr.employees e, hr.departments d
where e.department_id = 20
and d.department_id = 20;
v_rec emp_cur%rowtype; --커서이름으로 이용해서 레코드를 선언
begin
OPEN emp_cur;
loop
FETCH emp_cur INTO v_rec;
exit when emp_cur%notfound;
dbms_output.put_line(v_rec.employee_id); --레코드변수.컬렴명(select절 컬럼명)
dbms_output.put_line(v_rec.salary);
dbms_output.put_line(v_rec.department_name);
end loop;
dbms_output.put_line(emp_cur%rowcount);
CLOSE emp_cur;
end;
/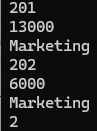
▶ 좀 더 간편하다.
▶ 출력할 땐 꼭 레코드변수.컬럼명을 써주는데 컬럼명은 select절에 있는 컬럼명을 쓰면 된다.
ex) 레코드 이용
declare
CURSOR emp_cur IS
select e.employee_id, e.salary, d.department_name
from hr.employees e, hr.departments d
where e.department_id = 20
and d.department_id = 20;
type rec_type is record(id number, sal number, name varchar2(30));
v_rec rec_type;
begin
OPEN emp_cur;
loop
FETCH emp_cur INTO v_rec;
exit when emp_cur%notfound;
dbms_output.put_line(v_rec.id); --레코드변수.컬렴명(select절 컬럼명)
dbms_output.put_line(v_rec.sal);
dbms_output.put_line(v_rec.name);
end loop;
dbms_output.put_line(emp_cur%rowcount);
CLOSE emp_cur;
end;
/
ex) 커서 선언 시 별칭을 쓸 경우
declare
CURSOR emp_cur IS
select e.employee_id id, e.salary sal, d.department_name name
from hr.employees e, hr.departments d
where e.department_id = 20
and d.department_id = 20;
v_rec emp_cur%rowtype;
begin
OPEN emp_cur;
loop
FETCH emp_cur INTO v_rec;
exit when emp_cur%notfound;
dbms_output.put_line(v_rec.id); --레코드변수.컬렴명(select절 컬럼명)
dbms_output.put_line(v_rec.sal);
dbms_output.put_line(v_rec.name);
end loop;
dbms_output.put_line(emp_cur%rowcount);
CLOSE emp_cur;
end;
/▶ 별칭을 쓸 경우엔 별칭이 필드명이 되기 때문에 출력문에 별칭을 적어주면 된다.
■ FOR LOOP
- 명시적 커서 사용 시 레코드 변수, OPEN, FETCH, CLOSE 작업을 자동으로 수행한다.
- FOR 레코드변수(암시적) IN 커서이름 LOOP
ex)
declare
CURSOR emp_cur IS
select e.employee_id id, e.salary sal, d.department_name name
from hr.employees e, hr.departments d
where e.department_id = 20
and d.department_id = 20;
begin
for v_rec in emp_cur loop
dbms_output.put_line(v_rec.id||' '||v_rec.sal||' '||v_rec.name);
end loop;
end;
/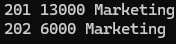
▶ 코드는 간결해졌지만 내부적으로 CURSOR의 메뉴얼대로 내부적으로 수행한 것이다.
■ subquery를 사용하여 cursor for loop (가장 편한 방법)
- 명시적 커서 속성은 사용할 수 없다. (커서를 선언하지 않았기 때문이다.)
begin
for v_rec in (select e.employee_id id, e.salary sal, d.department_name name
from hr.employees e, hr.departments d
where e.department_id = 20
and d.department_id = 20) loop
dbms_output.put_line(v_rec.id||' '||v_rec.sal||' '||v_rec.name);
end loop;
end;
/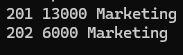
▶ 커서 선언을 하지 말고 for loop 안에서 select문을 써주면 된다.
문제) 2006년도에 입사한 사원들의 근무 도시이름별로 급여의 총액, 평균을 출력하세요.
내 답)
begin
for v_city in (select l.city city, sum(e.salary) sum_sal, trunc(avg(e.salary)) avg_sal
from hr.employees e, hr.departments d, hr.locations l
where e.department_id = d.department_id
and d.location_id = l.location_id
and e.hire_date between to_date('2006-01-01', 'yyyy-mm-dd')
and to_date('2006-12-31','yyyy-mm-dd')
group by l.city) loop
dbms_output.put_line(v_city.city||' 도시에 근무하는 사원들의 총액급여는 '||
trim(to_char(v_city.sum_sal, 'l999,999'))||'이고, 평균급여는 '||trim(to_char(v_city.avg_sal,'l999,999'))||'입니다.');
end loop;
end;
/▶ 하지만 24 row 결과가 나와서 JOIN을 24번 해야 한다.
강사님 답)
declare
CURSOR city_aggr_cur IS
select l.city, sum(e.sum_sal) sum_sal, avg(e.avg_sal) avg_sal
from(select department_id, sum(salary) sum_sal, avg(salary) avg_sal
from hr.employees
where hire_date >= to_date('2006-01-01', 'yyyy-mm-dd')
and hire_date < to_date('2007-01-01','yyyy-mm-dd')
group by department_id) e, hr.departments d, hr.locations l
where e.department_id = d.department_id
and d.location_id = l.location_id
group by l.city;
v_rec city_aggr_cur%rowtype;
begin
OPEN city_aggr_cur;
LOOP
FETCH city_aggr_cur INTO v_rec;
exit when city_aggr_cur%notfound;
dbms_output.put_line(v_rec.city||' 도시에 근무하는 사원들의 총액급여는 '||
trim(to_char(v_rec.sum_sal, 'l999,999'))||'이고, 평균급여는 '||trim(to_char(v_rec.avg_sal,'l999,999'))||'입니다.');
END LOOP;
CLOSE city_aggr_cur;
end;
/# 좀 더 쉽게 짜는 법
declare
CURSOR city_aggr_cur IS
select l.city, sum(e.sum_sal) sum_sal, avg(e.avg_sal) avg_sal
from(select department_id, sum(salary) sum_sal, avg(salary) avg_sal
from hr.employees
where hire_date >= to_date('2006-01-01', 'yyyy-mm-dd')
and hire_date < to_date('2007-01-01','yyyy-mm-dd')
group by department_id) e, hr.departments d, hr.locations l
where e.department_id = d.department_id
and d.location_id = l.location_id
group by l.city;
begin
for v_rec in city_aggr_cur loop
dbms_output.put_line(v_rec.city||' 도시에 근무하는 사원들의 총액급여는 '||
trim(to_char(v_rec.sum_sal, 'l999,999'))||'이고, 평균급여는 '||trim(to_char(v_rec.avg_sal,'l999,999'))||'입니다.');
END LOOP;
end;
/# FOR LOOP이용
begin
for v_rec in (select l.city, sum(e.sum_sal) sum_sal, avg(e.avg_sal) avg_sal
from(select department_id, sum(salary) sum_sal, avg(salary) avg_sal
from hr.employees
where hire_date >= to_date('2006-01-01', 'yyyy-mm-dd')
and hire_date < to_date('2007-01-01','yyyy-mm-dd')
group by department_id) e, hr.departments d, hr.locations l
where e.department_id = d.department_id
and d.location_id = l.location_id
group by l.city) loop
dbms_output.put_line(v_rec.city||' 도시에 근무하는 사원들의 총액급여는 '||
trim(to_char(v_rec.sum_sal, 'l999,999'))||'이고, 평균급여는 '||trim(to_char(v_rec.avg_sal,'l999,999'))||'입니다.');
END LOOP;
end;
/▶ 인라인뷰로 묶어서 처리함으로써 JOIN의 일 량을 5건으로 줄일 수 있다. 그러면 성능을 조금 더 높일 수 있다.

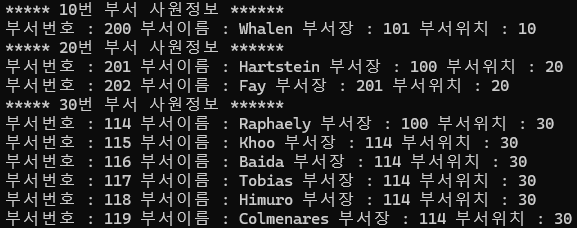
문제) 아래와 같이 출력하시오
********** 10번 부서 사원정보 **********
부서번호 : 10 부서이름 : Administration 부서장 : 200 부서위치 : 1700
200 Whalen Jennifer 4400 03/09/17 -> 10번 부서에 소속된 사원들의 정보 출력
********** 20번 부서 사원정보 **********
부서번호 : 20 부서이름 : Marketing 부서장 : 201 부서위치 : 1800
declare
type id_type is table of number;
v_id id_type := id_type(10,20,30);
v_dept hr.departments%rowtype;
begin
for i in v_id.first..v_id.last loop
select *
into v_dept
from hr.departments
where department_id = v_id(i);
dbms_output.put_line('***** '||v_dept.department_id||'번 부서 사원정보 ******');
for v_rec in (select * from hr.employees where department_id = v_id(i)) loop
dbms_output.put_line('부서번호 : '||v_rec.employee_id||' '||'부서이름 : '||v_rec.last_name||
' '||'부서장 : '||v_rec.manager_id||' '||'부서위치 : '||v_rec.department_id);
end loop;
end loop;
end;
/
'oracle PLSQL' 카테고리의 다른 글
| 2024.12.30 PL/SQL 8일차 (0) | 2024.12.30 |
|---|---|
| 2024.12.27 7일차 (2) | 2024.12.27 |
| 2024.12.24 PL/SQL 5일차 (5) | 2024.12.24 |
| 2024.12.23 PL/SQL 4일차 (0) | 2024.12.23 |
| 2024.12.20 PL/SQL 3일차 (6) | 2024.12.20 |



