■ 패키지 변수 초기화, one time only (에누리 없이 한 번만 사용)
- Package Body 끝에 있는 블록(BEGIN)은 한 번 실행되며 public, private 패키지 변수를 초기화하는 데 사용된다.
- 변수에 초기화된 값은 세션이 열려있는 동안에 지속적으로 사용한다.
- 중간에 변경되더라도 변경된 값은 사용하지 않는다.
- 커서의 지속상태와 같은 개념이라 생각하면 된다.
ex)
- 샘플 테이블 생성
create table hr.tax_rates
(rate_name varchar2(30),
rate_value number,
rate_date date);
- 값 넣기
insert into hr.tax_rates(rate_name, rate_value, rate_date)
values('TAX', 0.08, to_date('2025-01-06', 'yyyy-mm-dd'));
commit;
- 조회
select * from hr.tax_rates;
- 패키지 생성
create or replace package hr.taxes
is
g_tax number;
end taxes;
/
create or replace package body hr.taxes
is
begin
select rate_value
into g_tax
from hr.tax_rates
where rate_name = 'TAX';
end taxes;
/
- 호출환경
exec dbms_output.put_line(hr.taxes.g_tax);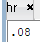
▶ 패키지 변수를 초기화 시키고 싶을 경우엔 Package Body에 BEGIN절을 이용하면 된다.
# 다른 세션에서 값을 1로 업데이트 했을 경우

# 초기화 시켰던 세션 창

■ Oracle Server는 2개의 엔진을 사용하여 PL/SQL 블록과 서브 프로그램을 실행한다.
- PL/SQL 엔진 : 프로시저문을 실행하지만 SQL문은 SQL 엔진에 전달한다.
- SQL 엔진 : SQL문을 구문분석, 실행하고 SELECT문의 실행결과를 PL/SQL 엔진에 전달한다.
# context switch (문맥전환)
- PL/SQL 엔진과 SQL 엔진 간에 문맥전환이 발생할 때 성능의 저하가 발생한다.
SQL 엔진 → PL/SQL 엔진 : 명시적 커서를 사용할 때 결과집합을 변수에 로드하는 FETCH 시점
PL/SQL 엔진 → SQL 엔진 : 반복문(PL/SQL) 안에 DML (SQL)이 있는 시점
■ bulk collect into 절
- SQL 엔진과 PL/SQL 엔진 사이의 문맥전환을 줄이는 방법
- 명시적 커서를 사용 시에 FETCH 시점이 문맥전환이 많이 발생한다. 이를 해결하기 위한 방법
ex) 사용해야 하는 이유
declare
cursor emp_cur is
select * -- SQL 엔진이 처리 (PL/SQL 엔진이 처리 못하기 때문이다.)
from hr.employees
where department_id = 20;
v_rec emp_cur%rowtype; -- PL/SQL 엔진이 처리
begin
open emp_cur; -- PL/SQL 엔진이 처리 (이 시점에 SQL 엔진에 전달한다.), SQL 엔진 작업이라 생각하면 된다.
loop
fetch emp_cur into v_rec;
exit when emp_cur%notfound;
dbms_output.put_line(v_rec.employee_id||' '||v_rec.first_name);
end loop;
close emp_cur;
end;
/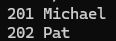
▶ 출력에 문제가 되진 않는다. emp_cur에 패치한 것을 v_rec에 전달을 해주는데 이 과정에서 SQL엔진과 PL/SQL엔진 사이에 문맥전환이 일어나는데 패치한 건수만큼 문맥전환이 일어나면서 처리성능이 안 좋아진다.
ex) bulk collect into 사용
declare
type tab_type is table of hr.employees%rowtype; -- nested 배열과 같다.
-- type tab_type is table of hr.employees%rowtype index by pls_integer; : 인덱스로 이용해도 된다.
v_tab tab_type;
begin
select *
bulk collect into v_tab -- 이 절에 2차원 배열을 담으라는 뜻
from hr.employees
where department_id = 20;
for i in v_tab.first..v_tab.last loop
dbms_output.put_line(v_tab(i).last_name);
end loop;
end;
/
▶ 한 건이 아니라 여러 건이기 때문에 배열로 받아야 되고, 컬럼이 여러 개이기 때문에 2차원 배열로 받아야 한다.
▶ 2차원 배열은 무조건 레코드로 만들어야 한다.
ex)
declare
cursor emp_cur is
select *
from hr.employees
where department_id = 20;
type tab_type is table of emp_cur%rowtype; -- cursor 기반으로 rowtype 할 것
v_tab tab_type;
begin
open emp_cur;
fetch emp_cur bulk collect into v_tab;
close emp_cur;
for i in v_tab.first..v_tab.last loop
dbms_output.put_line(v_tab(i).last_name);
end loop;
end;
/
ex) 파라미터 통한 커서를 만들 경우 (쓰는 경우 : 실행계획을 쉐어링 할 때)
declare
cursor emp_cur(p_id number) is
select *
from hr.employees
where department_id = p_id;
type tab_type is table of emp_cur%rowtype;
v_tab tab_type;
begin
open emp_cur(40);
fetch emp_cur bulk collect into v_tab;
close emp_cur;
for i in v_tab.first..v_tab.last loop
dbms_output.put_line(v_tab(i).last_name);
end loop;
end;
/
ex)
declare
type record_type is record(id number, name varchar2(30));
type table_type is table of record_type;
v_tab table_type;
begin
select e.employee_id, d.department_name
bulk collect into v_tab
from hr.employees e, hr.departments d
where e.department_id = d.department_id;
for i in v_tab.first..v_tab.last loop
dbms_output.put_line(v_tab(i).id||' '||v_tab(i).name);
end loop;
end;
/
▶ 서로 다른 유형의 데이터이기 때문에 레코드 배열을 만들어서 출력했다.
■ FORALL문 (8i부터 나옴)
- PL/SQL 엔진에서 SQL 엔진으로 전달함으로써 문맥전환을 한 번으로 줄이는 문
- 반복문 안에 DML문이 있는 경우 FORALL문으로 사용하면 문맥전환을 줄일 수 있다.
- DML외에 다른 게 오면 안 된다.
- DML 한 문장만 사용이 가능하고, merge문은 안 쓴다.
● 밑에 또 DML을 사용하고 싶으면 FORALL문을 또 쓰고 DML 적으면 된다.
ex)
begin
delete from hr.emp where department_id = 10;
delete from hr.emp where department_id = 20;
delete from hr.emp where department_id = 30;
end;
/▶ 실행계획을 쉐어링할만한데 상수값으로 고정시켜 놨기 때문에 좋진 않다.
# 개선 방법
declare
type numlist is table of number;
num_tab numlist := numlist(10, 20, 30);
begin
delete from hr.emp where department_id = num_tab(1);
dbms_output.put_line('Deleted '||sql%rowcount||' row(s)');
delete from hr.emp where department_id = num_tab(2);
dbms_output.put_line('Deleted '||sql%rowcount||' row(s)');
delete from hr.emp where department_id = num_tab(3);
dbms_output.put_line('Deleted '||sql%rowcount||' row(s)');
end;
/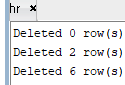
▶ 삭제 후 영향을 받은 row의 건 수를 출력한다.
# for문을 이용한 개선
declare
type numlist is table of number;
num_tab numlist := numlist(10, 20, 30);
begin
for i in num_tab.first..num_tab.last loop
delete from hr.emp where department_id = num_tab(i); -- SQL 엔진이 처리
dbms_output.put_line('Deleted '||sql%rowcount||' row(s)');
end loop;
rollback;
end;
/▶ 문제점은 반복을 3번 한다. 그 말은 문맥전환을 3번 했다는 뜻이다.
# FORALL 이용
- forall문 안에는 무조건 DML을 사용한다.
declare
type numlist is table of number;
num_tab numlist := numlist(10, 20, 30);
begin
forall i in num_tab.first..num_tab.last -- forall문
delete from hr.emp where department_id = num_tab(i); -- forall문
dbms_output.put_line('전체 삭제된 Deleted '||sql%rowcount||' row(s)');
rollback;
end;
/
▶ 한꺼번에 출력했기 때문에 전체 row의 건 수가 출력이 된다.
# 각 방마다 영향을 받은 row의 건 수를 출력하고 싶을 경우
declare
type numlist is table of number;
num_tab numlist := numlist(10, 20, 30);
begin
forall i in num_tab.first..num_tab.last -- forall문
delete from hr.emp where department_id = num_tab(i); -- forall문
dbms_output.put_line('전체 삭제된 Deleted '||sql%rowcount||' row(s)');
dbms_output.put_line(sql%BULK_ROWCOUNT(1)||' row deleted.');
dbms_output.put_line(sql%BULK_ROWCOUNT(2)||' row deleted.');
dbms_output.put_line(sql%BULK_ROWCOUNT(3)||' row deleted.');
rollback;
end;
/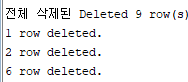
▶ sql%bulk_rowcount(n) : forall을 쓸 때는 그 배열 때문에 영향을 받은 row의 건 수를 알고 싶을 때 사용한다.
# for문을 써서 출력을 간단하게
declare
type numlist is table of number;
num_tab numlist := numlist(10, 20, 30);
begin
forall i in num_tab.first..num_tab.last -- forall문
delete from hr.emp where department_id = num_tab(i); -- forall문
dbms_output.put_line('전체 삭제된 Deleted '||sql%rowcount||' row(s)');
for i in num_tab.first..num_tab.last loop
dbms_output.put_line(sql%BULK_ROWCOUNT(i)||' row deleted.');
end loop;
rollback; -- test하기 편하게 rollback 쓴 거임
end;
/
# forall문 쓸 때 주의할 점
declare
type numlist is table of number;
num_tab numlist := numlist(10,11,0,12,20,0,30,199,2,0);
begin
forall i in num_tab.first..num_tab.last
delete from hr.emp where salary > 500000/ num_tab(i);
rollback;
end;
/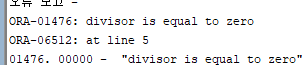
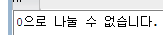
▶ 0으로 나눌 수 없기 때문에 에러 발생
# EXCEPTION 핸들링을 통한 에러 해결
declare
type numlist is table of number;
num_tab numlist := numlist(10,11,0,12,20,0,30,199,2,0);
begin
forall i in num_tab.first..num_tab.last
delete from hr.emp where salary > 500000/ num_tab(i);
rollback;
exception when ZERO_DIVIDE then
dbms_output.put_line('0으로 나눌 수 없습니다.');
end;
/
▶ 내부적으로 오류는 났지만 exception 핸들링을 통해 정상 종료가 되었다. (트랜잭션은 살아있다)
# 다음 데이터까지 출력하고 싶을 경우
- forall절에 SAVE EXCEPTIONS 사용 (옵션)
- 선언할 때 오류번호는 -24381로 고정
declare
type numlist is table of number;
num_tab numlist := numlist(10,11,0,12,20,0,30,199,2,0);
forall_error exception;
pragma exception_init(forall_error, -24381); -- forall문에서 오류가 뭔지 모르겠지만 오류번호는 -24381 고정
begin
forall i in num_tab.first..num_tab.last SAVE EXCEPTIONS -- 옵션, 별도의 공간에 exception발생한 것을 save해놓은다.
-- 값을 다 처리했으면 포인터는 exception절로 넘어간다.
delete from hr.emp where salary > 500000/ num_tab(i);
rollback;
exception when forall_error then
dbms_output.put_line('0으로 나눌 수 없습니다.');
end;
/
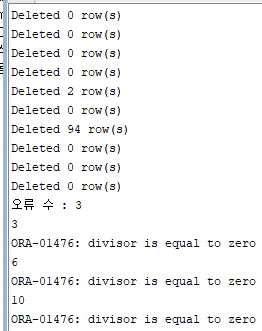
# 각 row의 영향을 받은 건 수와 개수를 알고 싶을 경우
declare
type numlist is table of number;
num_tab numlist := numlist(10,11,0,12,20,0,199,30,2,0);
forall_error exception;
pragma exception_init(forall_error, -24381); -- forall문에서 오류가 뭔지 모르겠지만 오류번호는 -24381 고정
v_error number;
begin
forall i in num_tab.first..num_tab.last SAVE EXCEPTIONS -- 옵션, 별도의 공간에 exception발생한 것을 save해놓은다.
-- 값을 다 처리했으면 포인터는 exception절로 넘어간다.
delete from hr.emp where salary > 500000/ num_tab(i);
exception when forall_error then
for i in num_tab.first..num_tab.last loop
dbms_output.put_line('Deleted '||sql%bulk_rowcount(i)||' row(s)');
end loop;
v_error := sql%bulk_exceptions.count;
dbms_output.put_line('오류발생한 수 : '||v_error);
for i in 1..v_error loop
dbms_output.put_line(sql%bulk_exceptions(i).error_index); -- 에러가 발생한 데이터의 index 알고 싶을 경우
end loop;
rollback;
end;
/▶ v_error 변수를 설정해서 에러 발생한 수를 알 수 있는 함수를 변수에 담아 좀 더 간결하게 한 것이다.
# exec 호출할 때 sqlerrm에 오류번호를 입력하면 메시지를 출력할 수 있다.
exec dbms_output.put_line(sqlerrm(-01403))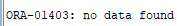
# 각 방에 exception이 발생했는데 무슨 오류인지 알고 싶을 경우
- sqlerrm(-sql%bulk_exceptions(i).error_code) : 오류번호는 음수로 되어있기 때문에 꼭 -붙여줘야 한다.
declare
type numlist is table of number;
num_tab numlist := numlist(10,11,0,12,20,0,199,30,2,0);
forall_error exception;
pragma exception_init(forall_error, -24381); -- forall문에서 오류가 뭔지 모르겠지만 오류번호는 -24381 고정
v_error number;
begin
forall i in num_tab.first..num_tab.last SAVE EXCEPTIONS -- 옵션, 별도의 공간에 exception발생한 것을 save해놓은다.
-- 값을 다 처리했으면 포인터는 exception절로 넘어간다.
delete from hr.emp where salary > 500000/ num_tab(i);
exception when forall_error then
for i in num_tab.first..num_tab.last loop
dbms_output.put_line('Deleted '||sql%bulk_rowcount(i)||' row(s)');
end loop;
v_error := sql%bulk_exceptions.count;
dbms_output.put_line('오류발생한 수 : '||v_error);
for i in 1..v_error loop
dbms_output.put_line(sql%bulk_exceptions(i).error_index); -- 에러가 발생한 데이터의 index 알고 싶을 경우
dbms_output.put_line(sqlerrm(-sql%bulk_exceptions(i).error_code)); -- 에러가 발생한 데이터의 오류메세지를 알고 싶을 경우
end loop;
rollback;
end;
/▶ 3,6번 방에 0으로 나눌 수 없어서 exception이 발생했다고 나오는 것이다.
ex) before
update hr.emp
set salary = salary * 1.1
where employee_id = 100;
select salary
from hr.emp
where employee_id = 100;▶ 성능적으로 좋지 않은 코드이다.
# 위에 코드 2개를 합치는 방법이 있다. (after)
declare
v_job varchar2(30);
v_sal number;
begin
update hr.emp
set salary = salary * 1.1
where employee_id = 100
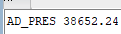
returning job_id, salary into v_job, v_sal;
dbms_output.put_line(v_job||' '||v_sal);
rollback;
end;
/
■ returning절 (9i부터 나옴)
- DML 작업 시에 FETCH절을 수행할 수 있다.
- 컬럼의 개수와 대응되게 into 옆에 적어줘야 한다.
# 만약 여러 건을 추출해야 할 경우
declare
type emplist is table of number;
emp_ids emplist := emplist(100, 101, 102, 104);
type rec_type is record(job varchar2(30), sal number);
type tab_type is table of rec_type;
emp_tab tab_type;
begin
forall i in emp_ids.first..emp_ids.last
update hr.emp
set salary = salary * 1.1
where employee_id = emp_ids(i)
returning job_id, salary bulk collect into emp_tab;
for i in emp_tab.first..emp_tab.last loop
dbms_output.put_line(emp_tab(i).job||' '||emp_tab(i).sal);
end loop;
rollback;
end;
/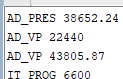
▶ 여러 건의 데이터가 들어있는 배열이 들어왔을 때는 각 방마다 입력값을 받는 emp_ids(i)를 적는다.
▶ 한꺼번에 데이터를 받아야기 때문에 문맥전환을 줄이기 위해 bulk collect into를 써준다.
▶ 그리고 job_id, salary 를 출력하고 싶으니까 2차원 배열을 생성해 준다.
▶ 만든 배열의 변수를 into 옆에(emp_tab) 적어준다.
▶ 문맥전환을 줄이기 위해 DML문장 update 하나만 있기 때문에 forall문을 이용하면 성능적으로 좋다.
'oracle PLSQL' 카테고리의 다른 글
| 2025.01.06 PL/SQL 12일차 (1) | 2025.01.06 |
|---|---|
| 2025.01.03 PL/SQL 11일차 (2) | 2025.01.03 |
| 2025.01.02 PL/SQL 10일차 (3) | 2025.01.02 |
| 2024.12.31 PL/SQL 9일차 (0) | 2024.12.31 |
| 2024.12.30 PL/SQL 8일차 (0) | 2024.12.30 |



