<< 시나리오 3 >> 백업 받지 않은 tablespace 데이터 파일 손상(redo 정보가 있을 경우)
select tablespace_name, file_name from dba_data_files;
# 샘플 tablespace 생성
create tablespace hr_tbs
datafile '/u01/app/oracle/oradata/ORA19C/hr_tbs01.dbf' size 10m;
# 데이터 파일에 대한 checkpoint 정보 확인
select name, checkpoint_change# from v$datafile;
▶ 방금 생성한 tablespace기 때문에 checkpoint가 다르다.
select * from v$log;
▶ 현재 tablespace 생성할 때 checkpoint 정보는 current한 그룹에 redo 정보가 저장되어 있다.
# 샘플 table 생성
create table hr.emp_new(id number)
tablespace hr_tbs;
insert into hr.emp_new(id)
values(1);
commit;▶ 생성한 table도 Oracle 딕셔너리 테이블에도 저장되고, redo 안 current 그룹 안에 저장이 된다.
# 장애 유발 전 확인
select name, checkpoint_change# from v$datafile;
# 장애 유발

# 상태 정보 확인

▶ 삭제는 됐지만 감지를 아직 못해서 online으로 뜬다.
▶ 백업 받지 않은 파일을 삭제했지만 복구가 가능하다. 그 이유는 redo에 정보가 있기 때문이다.
# offline으로 떨어뜨리는 작업

▶ no archive mode에서 offline으로 떨어뜨릴 때는 꼭 offline drop을 해줘야 한다!!
# 백업본이 없는 손상된 data file에 대해서 물리적인 파일을 생성


▶ 생성 후 확인해보면 10m가 데이터 파일이 생성이 되었고, 파일 안에는 아무것도 없는 깡통 파일이다.
# 새롭게 생성된 파일에 redo 정보를 이용해서 복구 작업

▶ redo 정보를 넣어주는 작업이다.
# recover 확인

▶ offline으로 변경되었다.
# 복구 수행한 데이터 파일을 online으로 변경 작업

# 생성한 table 조회해보기

※ no archive mode에서는 백업본을 받지 않은 tablespace를 삭제할 경우 복구가 불가능하다. <<시나리오 3>>은 tablespace 안에 있는 data file을 손상시킨 것이고, no archive mode이기 때문에 복구가 가능한 것이다.
# 샘플 tablespace 삭제
- test용이니까 삭제한 것
drop tablespace hr_tbs including contents and datafiles;
<< 시나리오 4 >> 백업 받지 않은 tablespace 데이터 파일 손상(redo 정보가 없을 경우)
# redo 정보 확인
select * from v$log;
# 샘플 tablespace 생성
create tablespace hr_tbs
datafile '/u01/app/oracle/oradata/ORA19C/hr_tbs01.dbf' size 10m;select tablespace_name, file_name from dba_data_files;
# checkpoint 상태 정보 확인
select name, checkpoint_change#, status from v$datafile;
# redo 정보 확인
select * from v$log;
# 샘플 table 생성
create table hr.emp_new(id number)
tablespace hr_tbs;
insert into hr.emp_new(id)
values(1);
commit;
select * from v$log;
# log switch 유발

# redo 정보 확인

# log switch가 발생했기 때문에 수위가 맞춰줬는지 확인
select name, checkpoint_change#, status from v$datafile;
# DB level에서도 확인해보기
select name db_name, open_mode, log_mode,checkpoint_change# from v$database;
▶ checkpoint가 맞춰져 있다.
# 장애 유발

# 데이터 상태 정보 확인
select name, checkpoint_change#, status from v$datafile;
# offline으로 떨어뜨린다.
alter database datafile '/u01/app/oracle/oradata/ORA19C/hr_tbs01.dbf' offline drop;
▶offline하면 무조건 recover라고 뜨는데 꼭 복구해야 한다.
# 백업본이 없는 손상된 데이터 파일에 대해서 물리적인 파일 생성
alter database create datafile '/u01/app/oracle/oradata/ORA19C/hr_tbs01.dbf';
▶ 꼭 control file이 가지고 있는 위치여야 한다.
# 새롭게 생성한 파일에 redo 정보를 이용해서 복구 작업

▶복구 작업을 시도하려 했지만 redo 정보가 없어서 오류가 발생했고, 복구 작업을 할 수 없다.
# 쓸 수 없는 tablespace이기 때문에 삭제해야 한다.
select name, checkpoint_change#, status from v$datafile;
alter database datafile '/u01/app/oracle/oradata/ORA19C/hr_tbs01.dbf' online;
▶ 손상된 데이터 파일에 대해서는 online으로 변경할 수 없다.
# 삭제
drop tablespace hr_tbs including contents and datafiles;
▶ 손상된 데이터 파일이 있는 tablespace를 지금은 삭제할 수 없다.
# 삭제를 위해 DB를 정상 종료 후 올리기
- recover라고 적혀있는 것은 checkpoint가 발생하지 않는다.

# 데이터 파일 정보 확인

# drop

▶ 삭제하기 위해선 DB를 내렸다 올리고 삭제하면 된다.
# 다음 시나리오를 위해 원복

<< 시나리오 5 >> SYSTEM 데이터 파일 손상 (백업 이후에 redo 정보가 있을 경우)
select name db_name, open_mode, log_mode,checkpoint_change# from v$database;
select * from v$log;
# 장애 유발

# 딕셔너리 테이블 조회

▶ 조회가 되는 이유는 shared pool 안에 data buffer cache에 올려놓은 정보가 있을 수도 있고, 없을 수도 있다. 하지만 있는 정보여서 조회가 된 것이다.
# checkpoint 발생
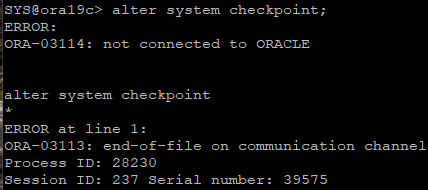

▶ sytem 파일이 없기 때문에 에러가 발생한 것이다.
# DB 상태 정보 확인

▶터미널이 끊어져서 에러가 발생한 것이다.
# 세션을 다시 접속

▶ DB가 불안정하게 내려간 것이다.
# DB 띄우기

# recover file 확인

▶system 파일은 1번이다.
# system file online, offline 상태 확인

# DB 상태 확인

▶ system data file이 손상되었을 경우 mount 단계에서 복구 작업 진행해야 한다.
# 가장 최근에 백업 받은 system datafile을 찾아서 restore

# 백업 이후에 변경 정보(redo)를 이용해서 복구 작업 수행

# DB open
<< 시나리오 6 >> SYSTEM 데이터 파일 손상(백업 이후에 redo 정보가 없을 경우)
select name db_name, open_mode, log_mode,checkpoint_change# from v$database;
select * from v$log;
select name, checkpoint_change#, status from v$datafile;
# redo가 없어야 되기 때문에 log switch 발생시키기
alter system switch logfile;
alter system switch logfile;
alter system switch logfile;select * from v$log;
# 장애 유발

# checkpoint 발생


▶ 실행됐다고만 뜬 거지 에러 발생이다. alert log에는 에러가 발생한 게 뜬다.
# hr로 접속해보기
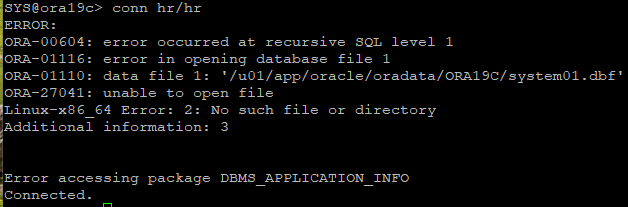
▶ system 파일이 깨졌기 때문에 접속이 불가능하다.
# sys 접속

▶ 작업이 될 수도 있지만 파일은 깨진 상태이다.
# DB 비정상으로 내리고 다시 올리기
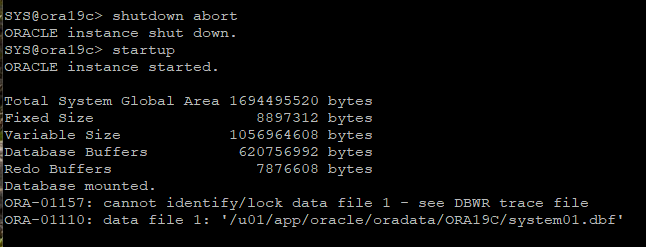
# recover file 확인
select * from v$recover_file;
# 최근에 백업 받은 system data file을 찾아서 restore

# 백업 이후에 변경 정보(redo)를 이용해서 복구 작업하려고 시도했지만 redo 정보가 없어서 복구 실패(완전복구 실패)

# DB 비정상 종료 후 띄우기

<< 시나리오 7 >> undo data file 손상(백업 이후에 redo 정보가 있을 경우)
select a.file#, b.name tbs_name, a.name file_name, a.checkpoint_change#, a.status
from v$datafile a, v$tablespace b
where a.ts# = b.ts#;
# undo 정보 확인
select segment_id, segment_name, owner, tablespace_name,status
from dba_rollback_segs;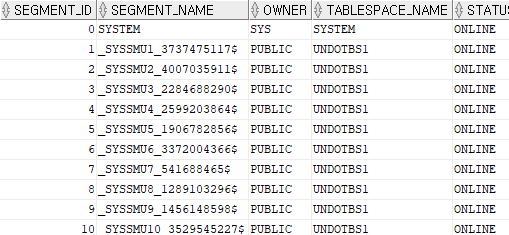
# 트랜잭션 걸려있는 session 확인
select s.username, s.sid, s.serial#, r.name, t.ubafil, t.xidusn, t.ubablk, t.used_ublk
from v$session s, v$transaction t, v$rollname r
where s.taddr = t.addr
and t.xidusn = r.usn;
▶트랜잭션을 걸고 있는 게 없기 때문에 아무것도 안 뜬 것이다.
<< hr session >>
select salary
from hr.employees
where employee_id = 100;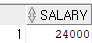
# undo 발생
update hr.employees
set salary = salary * 1.1
where employee_id = 100;
<< SYS session >>
select s.username, s.sid, s.serial#, r.name undo_segment, t.ubafil, t.xidusn, t.ubablk, t.used_ublk
from v$session s, v$transaction t, v$rollname r
where s.taddr = t.addr
and t.xidusn = r.usn;
▶ update가 되면서 undo가 발생되어서 트랜잭션 정보 확인하면 현재 트랜잭션이 걸려있는 상태(commit, rollback을 아직 하지 않았기 때문)로 가는 중이다.
# log switch 발생했는지 확인
select * from v$log;
▶ log switch 발생하지 않았다.
# 장애 유발

# checkpoint 발생

▶ 있어야 될 undo가 없어서 에러가 발생한다.
▶ 현재 session이 끊어진 상태이다.
# sysdba로 접속

▶ DB가 불안전하게 내려간 상태이다. (idle instance)
# DB 띄우기

▶ open 시점에 에러 발생
# 문제되는 파일 정보 확인

select name, checkpoint_change#, status from v$datafile;
▶ undo는 offline을 할 수 없다.
# DB 상태 확인

# 가장 최근에 받은 백업 데이터 파일을 찾아 restore

# 백업 이후에 변경 정보(redo)를 적용

# DB open

# 트랜잭션 확인
select s.username, s.sid, s.serial#, r.name undo_segment, t.ubafil, t.xidusn, t.ubablk, t.used_ublk
from v$session s, v$transaction t, v$rollname r
where s.taddr = t.addr
and t.xidusn = r.usn;
▶commit, rollback을 하지 않았기 때문에 recover 시 자동 rollback이 되었다.
select segment_id, segment_name, owner, tablespace_name,status
from dba_rollback_segs;
# 위에서 수정한 100번 사원 조회
select salary
from hr.employees
where employee_id = 100;
▶자동 rollback이 되었기 때문에 이전값이 나온다.
<< 시나리오 8 >> undo data file 손상(백업 이후에 redo 정보가 없을 경우)
select name db_name, open_mode, log_mode,checkpoint_change# from v$database;
select segment_id, segment_name, owner, tablespace_name,status
from dba_rollback_segs;
# 트랜잭션 정보 확인
select s.username, s.sid, s.serial#, r.name undo_segment, t.ubafil, t.xidusn, t.ubablk, t.used_ublk
from v$session s, v$transaction t, v$rollname r
where s.taddr = t.addr
and t.xidusn = r.usn;
<< hr session >>
# 트랜잭션 발생
update hr.employees
set salary = salary * 1.1
where employee_id = 100;
select salary
from hr.employees
where employee_id = 100;
<< SYS session >>
# 다시 트랜잭션 정보 확인

# 특정 session을 킬 시키고 싶을 경우 (실행은 하지말 것)
alter system kill session '262,28539' immediate▶ PMON이 찾아서 자동 rollback한다.
# 현재 redo 정보
select * from v$log;
# log switch 발생 (redo 정보 없애기 위함)
alter system switch logfile;
alter system switch logfile;
alter system switch logfile;
# 장애 유발

# checkpoint 발생

▶ 아까는 에러가 발생했지만 이번엔 오류가 나지 않았다. 오류가 날 수도 있고, 안 날 수도 있다.
▶ 꼭 alert log에 에러메세지가 뜨는 걸 확인하고 작업해야 undo tablespace 삭제 시 오류가 안 나고, offline으로 떨어뜨리고 확인할 때 needs recovery라 안 뜬다.
<< new hr session >>
- 에러 메세지 뜨는 동안 hr session하나 새로 열어서 수정 작업하면 에러메세지가 뜬다. 그러면 이제 계속 복구 작업 진행하면 된다.


▶ undo에 문제가 발생해도 감지가 더디게 된 것이고, 접속이 가능하다.
▶ 장애를 유발해도 수정이 가능하다.
▶data buffer cache에 어느 정도 정보가 들어있으니 에러가 발생하지 않았지만 에러가 나야 정상이다.
<< SYS session >>
select s.username, s.sid, s.serial#, r.name undo_segment, t.ubafil, t.xidusn, t.ubablk, t.used_ublk
from v$session s, v$transaction t, v$rollname r
where s.taddr = t.addr
and t.xidusn = r.usn;
# DB 내리기

▶undo에 문제가 있기 때문에 session이 끊어져서 에러가 발생
# startup

# recover 대상 파일 확인

select a.file#, b.name tbs_name, a.name file_name, a.checkpoint_change#, a.status
from v$datafile a, v$tablespace b
where a.ts# = b.ts#;
# 가장 최근에 받은 놓은 백업 파일을 찾아서 restore

# 백업 이후에 변경정보(redo)를 이용해서 복구 작업

▶작업을 시도했지만 redo 정보가 없어서 실패한 것이다.
# offline으로 떨어뜨린다.
alter database datafile '/u01/app/oracle/oradata/ORA19C/undotbs01.dbf' offline drop;select a.file#, b.name tbs_name, a.name file_name, a.checkpoint_change#, a.status
from v$datafile a, v$tablespace b
where a.ts# = b.ts#;
# DB open

# 다시 조회

▶ 바뀌지 않았다.
# offline 확인
select segment_id, segment_name, owner, tablespace_name,status
from dba_rollback_segs;
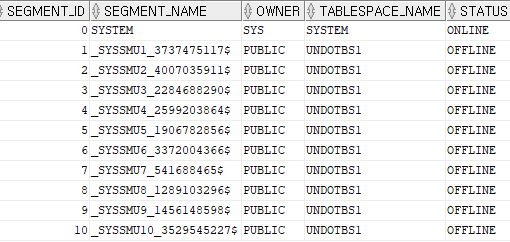
- needs recovery라고 떠도 무시해도 된다. (만약 그렇게 뜨면 shutdown immediate하면 된다.)
# 새로운 UNDO tablespace 생성하고 지정

# 기존 undo를 새로운 undo로 지정
alter system set undo_tablespace = undo1;select segment_id, segment_name, owner, tablespace_name,status
from dba_rollback_segs;▶ 새롭게 만든 undo에 대해선 online으로 뜨고, 전에 undo는 offline으로 바뀐다.
# 기존에 문제있는 undo 삭제
drop tablespace undotbs1 including contents and datafiles;
※ 8번 시나리오 다시 Test하기 위해서 원복하는 법



▶기존에 생성했던 undo01이 그대로 있기 때문에 삭제해줬다.


