1. 모든 DBMS 안에 날짜 형식의 데이터는 숫자형으로 들어가기 때문에 내부에 수치형 자료로 들어가 있다. (날짜 형식도 연산이 가능하다.)
ex 1)
select
sysdate + 5,
sysdate - 4
from dual;
ex 2) 오늘 시간을 문자형으로 바꿔서 초단위까지 보여주고 싶을 경우
select
to_char(sysdate,'yyyy-mm-dd hh24:mi:ss.sssss')
from dual;
# hh만 썼을 땐 오전, 오후 구분이 안 간다. 하지만 뒤에 am이나 pm 둘 중 아무거나 써주면 현재 오전인지 오후인지 알려준다.
select
to_char(sysdate,'yyyy-mm-dd hh:mi:ss.sssss pm')
from dual;
# 현재 기원전인지 후인지 알고 싶을 경우 (bc, ad 둘 중 편한 거 쓰면 된다.)
select
to_char(sysdate,'bc yyyy-mm-dd hh:mi:ss.sssss pm')
from dual;
2. to_char
- number를 char형으로 변환하는 함수
- 숫자형일 땐 천 단위 표시나 달러 표시를 할 수 없기 때문에 형변환을 해줘야 한다.
- to_char(숫자, '숫자모델요소')
# 숫자 모델 요소
- l : 로컬 통화 기호
- 9 : 숫자를 나타내는 기호 (그 위치값에 숫자가 없으면 출력을 안 한다.)
- 0 : 숫자를 나타내는 기호 (그 위치값에 숫자가 없으면 강제로 0을 출력한다.)
- $ : 달러 기호
- , : 천단위 구분자
- . : 소수점 구분자
- g : 천단위 구분자 (지역마다 자동으로 반환하고 싶을 때)
- d : 소수점 구분자 (지역마다 자동으로 반환하고 싶을 때)
- mi : 오른쪽에 음수 부호 표시
- pr : 음수일 경우 괄호나 ( <> )로 묶기
- s : 음수 또는 양수 부호 표현
ex 1)
select
salary,
to_char(salary, 'l999,999.00'),
to_char(salary, 'l999g999d00'),
to_char(salary, '000,999')
from hr.employees;
ex 2)
select
- 100,
to_char(-100, '999mi'),
to_char(-100, '999pr'),
to_char(-100, 's999'),
to_char(100, 's999')
from dual;
# 만약 프랑스 지역에서 접속하고 싶은 경우
alter session set nls_territory = france;
alter session set nls_language = french;select
salary,
to_char(salary, 'l999,999.00'), -- 천단위 구분자가 다르기 때문에 이 부분은 틀리다.
to_char(salary, 'l999g999d00'),
to_char(salary, '000,999')
from hr.employees;- 저 부분이 프랑스는 다르기 때문에 지워줘야 한다.
- SQL은 날짜와 지역에 종속받기 때문에 지역에 맞게 형식을 적어줘야 한다.
ex) 프랑스 지역에서 우리나라 형식으로 날짜 형식을 바꾸고 싶을 경우
select
to_char(sysdate, 'yyyy-mm-dd')
from dual;- 지역은 프랑스지만 출력 형식은 우리나라로 출력이 된다.
3. overloading, 객체지향 프로그래밍 기능
- 동일한 이름의 함수를 생성할 수 있다.
- to_char(숫자, '숫자모델요소')
- to_char(날짜, '날짜모델요소')
# 암시적으로 형변환이 발생해서 연산이 된다.
select '1' + 1
from dual;- 내부적으로는 to_number('1') + 1로 바뀌어서 출력한다.
to_number
- 문자형(숫자)을 숫자형으로 변환하는 함수
- to_number(문자(숫자), '숫자모델요소(생략가능)')
select to_number('1','9') + 1,
to_number('100') + 1,
to_number('100','999') + 1,
to_number('one') + 1 -- 오류발생
from dual;
select
hire_date,
to_char(hire_date, 'mm'),
to_number(to_char(hire_date, 'mm'))
from hr.employees;- 입사한 날짜에 mm을 통해 입사한 달을 출력하고, 그 밑에는 입사한 달이 숫자로 보여도 문자형이기 때문에 숫자형으로 변환하고 싶으면 to_number로 묶어서 숫자형으로 형변환 시켜준다.
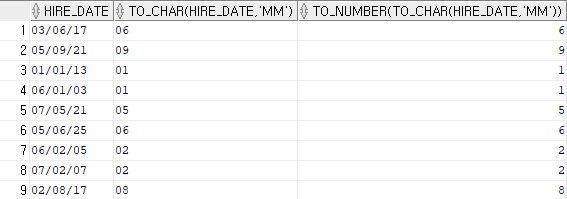
# 입사한 달을 뽑고 싶은데 문자형과 숫자형으로 출력하고 싶을 경우
- 문자형인데 0을 제거하고 싶을 땐 fm 사용
select
hire_date,
to_char(hire_date, 'mm'),
to_char(hire_date, 'fmmm'),
to_number(to_char(hire_date, 'mm'))
from hr.employees;
문제 1) 짝수 달에 입사한 사원들의 정보를 출력하시오.
select *
from hr.employees
where mod(to_number(to_char(hire_date, 'mm')),2) = 0;- 먼저 입사한 달을 알아야 하니까 to_char를 써서 mm을 통해 달만 출력한다.
- 하지만 숫자로된 문자형 데이터이기 때문에 연산이 안 돼서 to_number를 통해 숫자형으로 변환해준다.
- mod를 통해 변환환 입사 달을 2로 나눴을 때 나머지가 0이면 짝수이기 때문에 = 0으로 마무리해 준다.

문제 2) 2006년도에 입사한 사원들의 정보를 출력하시오. (미국 지역에서 출력하고 싶을 때도 출력하기)
- 한국
select *
from hr.employees
where hire_date >= '06/01/01'
and hire_date <= '06/12/31';
- 미국
select *
from hr.employees
where hire_date >= '01-jan-06'
and hire_date <= '31-dec-06';to_date
- 문자 날짜를 날짜형으로 변환하는 함수
- to_date('문자 날짜', '날짜모델요소')
# 어느 지역, 언어든 날짜가 허용되게 하고 싶을 경우 (이렇게 쓰는 습관 기르기!!)
select *
from hr.employees
where hire_date >= to_date('2006-01-01', 'yyyy-mm-dd')
and hire_date <= to_date('2006-12-31', 'yyyy-mm-dd');# 만약 주문 날짜, 시간까지 필요한 정보일 경우엔 시간까지 다 적어주거나 2번째처럼 비교해준다. (2가지 다 같은 방법)
select *
from hr.employees
where hire_date between to_date('2006-01-01', 'yyyy-mm-dd')
and to_date('2006-12-31 23:59:59', 'yyyy-mm-dd');select *
from hr.employees
where hire_date >= to_date('2006-01-01', 'yyyy-mm-dd')
and hire_date < to_date('2007-01-01', 'yyyy-mm-dd');4. null
- null은 사용할 수 없거나, 할당되지 않았거나, 알 수 없거나, 적용할 수 없거나, 계산할 수 없는 값, 결측값
- null은 0, 공백이 아니다.
1) nvl : null값을 실제값으로 리턴하는 함수 (인수값 2개만 가능)
→ nvl(컬럼(문자, 숫자, 날짜), 실제값)
→ 주의사항 : nvl 함수는 두 개의 인수 데이터 타입이 일치해야 한다.
select
employee_id,
salary,
commission_pct,
salary * 12 + salary * 12 * nvl(commission_pct,0) annual_salary
from hr.employees;
select
employee_id,
commission_pct,
nvl(commission_pct, 0),
nvl(commission_pct, 'no comm')
from hr.employees;- 실행하면 오류가 뜬다. 이유는 commission_pct는 숫자형이고, 'no comm'은 문자형이기 때문에 서로 타입이 안 맞아서 오류가 뜬다.
- 그래서 nvl(commission_pct, 'no comn') -> nvl(to_char(commission_pct, 'no commn') 처럼 형변환을 시켜줘야 출력이 됨.
2) nvl2
- nvl2(인수1, 인수2, 인수3)
- 첫 번째 인수1이 null이 아니면 인수2를 수행하고 null이면 인수3을 실행한다.
- 인수2, 인수3의 데이터 타입이 일치해야 한다.
select
employee_id,
salary,
commission_pct,
salary * 12 + salary * 12 * nvl(commission_pct,0) annual_salary_1,
nvl2(commission_pct, salary * 12 + salary * 12 * commission_pct, salary * 12) annual_salary_2
from hr.employees;
select
employee_id,
commission_pct,
nvl(commission_pct, 0),
nv2(commission_pct, commission_pct, 'no comm')
from hr.employees;- 위에서처럼 데이터 타입이 맞지 않아 오류가 발생한다.
↓ 해결방법
select
employee_id,
commission_pct,
nvl(commission_pct, 0),
nvl2(commission_pct, to_char(commission_pct), 'no comm')
from hr.employees;
3) coalesce (인수1,인수2,인수3,...인수n)
- 첫 번째 인수1이 null이면 인수2 실행하고 인수2가 null이면 인수3을 수행, 인수3이 null이면 다음 인수를 수행한다.
- 즉, null이 아닌 값을 찾을 때까지 인수를 수행하는 함수
select
employee_id,
salary,
commission_pct,
coalesce(salary * 12 + salary * 12 * commission_pct, salary * 12, 0) annual_salary_3
from hr.employees;
▶ coalesce 함수도 마찬가지로 데이터 타입이 맞지 않으면 오류가 발생하기 때문에 데이터 타입을 잘 맞춰줘야 한다.
4) nullif
- nullif(인수1, 인수2)
- 두 인수값을 비교해서 같으면 null을 리턴하고 같지 않으면 인수1을 리턴하는 함수
select
employee_id,
length(last_name),
length(first_name),
nullif(length(last_name), length(first_name))
from hr.employees;- last_name 길이와 first_name 길이를 nullif 이용해 비교해서 같으면 null을 출력하고, 다르면 last_name 길이를 출력한다.

■ 조건제어문
- SQL문에서는 IF문을 사용해서 조건 제어를 할 수 없다.
- decode 함수, case 표현식(9i 버전)
▣ PLSQL IF 문법
IF 기준값 = 비교값1 THEN 참값1
ELSIF 기준값 = 비교값2 THEN 참값2
ELSIF 기준값 = 비교값3 THEN 참값3
.
.
ELSE 기본값
END IF;
# DECODE 함수는 기준값과 비교값을 같다.(=) 비교연산자만 사용한다.
select
employee_id,
salary,
job_id,
decode(job_id,
'IT_PROG',salary * 1.1, -- 소문자로 쓰면 salary값 그대로 출력됨 (대소문자 구분)
'ST_CLERK', salary * 1.2,
'SA_REP', salary * 1.3,
salary) revised_salary
from hr.employees;
# CASE 표현식
- 기준값과 비교값의 대해서 모든 비교연산자를 사용할 수 있다. (유연성이 좋음)
CASE 기준값 (내부적으로 기준값 = 비교값)
when 비교값1 then 참값1
when 비교값2 then 참값2
when 비교값3 then 참값3
.
.
.
ELSE
기본값
END-- 비교연산자 (=, >, >=, <, <=, <>, !=, ^=, in, between and, like)
-- 논리연산자 (not, and, or)
CASE 기준값 (내부적으로 기준값 = 비교값)
WHEN 기준값 != 비교값1 THEN 참값1
WHEN 기준값 >= 비교값2 THEN 참값2
WHEN 기준값 >= 비교값3 and 기준값 <=비교값3 THEN 참값3
.
.
.
ELSE
기본값
ENDselect
employee_id,
salary,
job_id,
case job_id,
when 'IT_PROG' then salary * 1.1
when 'ST_CLERK' then salary * 1.2
when 'SA_REP' then salary * 1.3
else
salary
end as revised_salary
from hr.employees;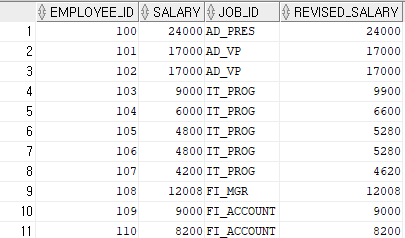
▶jod_id를 통해 만약 IT_PROG라는 id가 있으면 salary * 1.1을 해준다.
▶만약 ST_CLERK가 있으면 salary * 1.2를 해준다.
▶SA_REP가 있으면 salary * 1.3을 해준다.
▶ 그 외에 id들은 기본 salary 출력해준다.
문제) 사원들의 급여를 기준으로 등급을 출력해 주세요.
예시 - 0 ~ 4999 : low
5000 ~ 9999 : medium
10000 ~ 19999 : good
20000 ~ : excellent
select
employee_id,
salary,
case
when salary between 0 and 4999 then 'low'
when salary >= 5000 and salary < 10000 then 'medium'
when salary >= 10000 and salary < 20000 then 'good'
else
'excellent'
end as 등급
from hr.employees;
# decode 함수, case 표현식에서 null check 방법 (많이 쓰기 때문에 중요!)
ex) decode에서 체크하는 방법 (null만 쓸 수 있다.)
select
employee_id,
salary,
commission_pct,
decode(commission_pct,
null, salary * 12,
salary *12 + salary * 12 * commission_pct) annual_salary
from hr.employees;
ex) case에서 체크하는 방법 (is null, is not null 이용!)
select
employee_id,
salary,
commission_pct,
case
when commission_pct is null then salary * 12
else
salary * 12 + salary * 12 * commission_pct
end annual_salary
from hr.employees;select
employee_id,
salary,
commission_pct,
case
when commission_pct is not null then salary * 12
else
salary * 12 + salary * 12 * commission_pct
end annual_salary
from hr.employees;
ex) 95-10-27
select sysdate from dual;
- 1924/12/02
- 2024/12/02
- 구분이 안 감
select
to_char(to_date('95-10-27','yy-mm-dd'), 'yyyy-mm-dd'),
to_char(to_date('95-10-27','rr-mm-dd'), 'yyyy-mm-dd')
from hr.employees;
▶ yy : 현재 년도의 세기를 반영 ex) 95-10-27 이면 현재 21세기이기 때문에 2095-10-27 출력
▶ rr : 2000년도부터는 표기법을 자동화로 변경해준다.
| 데이터 입력 연도(년도) | ||
| 현재 연도 | 0 ~ 49 | 50 ~ 99 |
| 0 ~ 49 | 반환 날짜는 현재 세기를 반영 | 반환 날짜는 이전 세기를 반영 |
| 50 ~ 99 | 반환 날짜는 이후 세기를 반영 | 반환 날짜는 현재 세기를 반영 |
ex)
| 현재 연도 | 데이터 입력 날짜 | yy | rr |
| 1994 | 95-10-27 | 1995 | 1995 |
| 1994 | 17-10-27 | 1917 | 2017 |
| 2001 | 17-10-27 | 2017 | 2017 |
| 2048 | 52-10-27 | 2052 | 1952 |
| 2051 | 47-10-27 | 2047 | 2147 |
그룹함수 (여러 행 함수)
- 여러 행당 하나의 결과를 반환하는 함수
- sum, avg, median, variance, stddev, max, min, coount
- 그룹함수에 입력하는 값이 숫자형만 입력해야 하는 그룹함수 : sum, avg, median, variance, stddev
- 그룹함수에 입력하는 값이 모든 데이터 타입 가능한 그룹함수 : max, min, count
- 그룹함수는 null이 포함되지 않는다. 단 count(*)만 null이 포함한 행수를 구할 수 있다.
ex)
select count(last_name),
count(hire_date),
max(last_name),
max(hire_date),
min(last_name),
min(hire_date)
from hr.employees;
1) count : 행의 수를 구하는 함수
- count 안에 컬럼을 적을 경우엔 null을 포함하지 않고 행의 수를 출력해준다.
select count(*) -- null 포함
from hr.employees;
select count(commission_pct) -- null 포함되지 않는다.
from hr.employees;
select count(distinct department_id) -- 중복을 제거하고 출력한다.
from hr.employees;
2) sum : 합
ex1) salary에 총합을 알고 싶은 경우
select sum(salary)
from hr.employees;
ex 2) department_id가 50인 사람들의 급여 총합을 알고 싶은 경우
select sum(salary)
from hr.employees
where department_id = 50;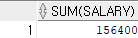
3) avg : 평균
- avg 함수의 의미 : ex) 1, null, 3의 평균을 구할 때 -> (1+3) / 2를 한다. (null을 빼고 연산을 함)
ex 1) salary 값의 평균을 알고 싶을 경우
select avg(salary)
from hr.employees;
ex 2) department_id가 50인 사람들의 급여 평균을 알고 싶은 경우
select avg(salary)
from hr.employees
where department_id = 50;
ex 3) null을 제외한 평균
select avg(commission_pct)
from hr.employees;
ex 4) null 포함한 평균
select avg(nvl(commission_pct,0))
from hr.employees;
4) median : 중앙값
select avg(salary), median(salary)
from hr.employees;
5) variance : 분산
- 분산 공식 : 편차 제곱의 평균
- 이해를 돕기 위한 분산 구하는 방법 예) 15, 17, 16, 14, 18
- 평균을 구한다 : (15+17+16+14+18) / 5 = 16
- 편차 : 순서대로 -1, 1, 0, -2, 2
- 분산 = [(-1)² + 1² + 0² + (-2)² + 2²] / 5 = 2
select avg(salary), median(salary), variance(salary)
from hr.employees;
6) stddev : 표준편차
- 표준편차 : √분산
select stddev(salary)
from hr.employees;
7) max, min
- max : 최댓값
- min : 최솟값
select max(salary), min(salary), max(salary) - min(salary) 범위
from hr.employees;
'oracle SQL' 카테고리의 다른 글
| 2024.12.04 6일차 수업 (0) | 2024.12.04 |
|---|---|
| 2024.12.03 5일차 수업 (2) | 2024.12.03 |
| 2024.11.29 3일차 수업 (0) | 2024.11.29 |
| 2024.11.28 2일차 수업 (4) | 2024.11.28 |
| 2024.11.27 첫 수업 (4) | 2024.11.28 |



