문제 1) 80 부서에 근무하는 사원들의 last_name, job_id, department_name, city를 출력하시오.
select e.last_name, e.job_id, d.department_name, l.city
from hr.employees e, hr.departments d, hr.locations l
where e.department_id = d.department_id
and d.location_id = l.location_id
and e.department_id = 80;▶ 하지만 결과가 같다면 더 성능 좋게 셀프 튜닝으로 join 할 수도 있다. (카티션 곱 유발)
▶ 문장 튜닝할 때 더 자세하게 배울 예정이다.
select e.last_name, e.job_id, d.department_name, l.city
from hr.employees e, hr.departments d, hr.locations l
where d.department_id = 80
and d.location_id = l.location_id
and e.department_id = 80;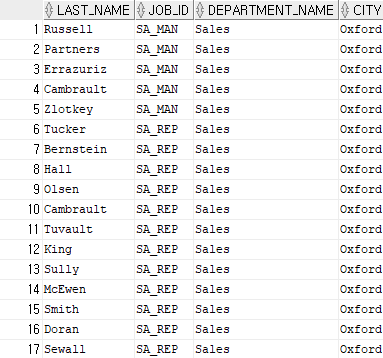
문제 2) Toronto 도시에서 근무하는 모든 사원의 last_name, job_id, department_id, department_name 출력하시오.
내 답 -
select e.last_name, e.job_id, d.department_id, d.department_name
from hr.employees e, hr.departments d, hr.locations l
where e.department_id = d.department_id
and d.location_id = l.location_id
and l.city = 'Toronto';
교수님 답 -
select e.last_name, e.job_id, d.department_id, d.department_name
from hr.locations l, hr.departments d, hr.employees e
where l.city = 'Toronto'
and l.location_id = d.location_id
and d.department_id = e.department_id;
1. outer join
- 키값이 일치되는 데이터 또는 키값이 일치되지 않은 데이터도 출력하는 조인
- 한쪽에만 (+) 표현한다.
- 양쪽에 (+)를 수행하면 오류 발생
ex 1)
select e.employee_id, e.last_name, d.department_name
from hr.employees e, hr.departments d
where e.department_id = d.department_id;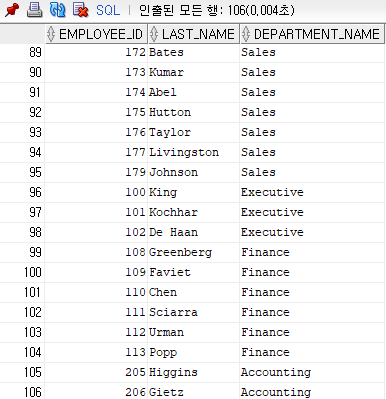
▶ 실행하면 m쪽 집합 x 1쪽 집합은 m쪽 집합이기 때문에 employees 테이블은 총 107건인데 106건이 나오기 때문에 누락된 한 건도 출력해줘야 한다.
select e.employee_id, e.last_name, d.department_name
from hr.employees e, hr.departments d
where e.department_id = d.department_id(+);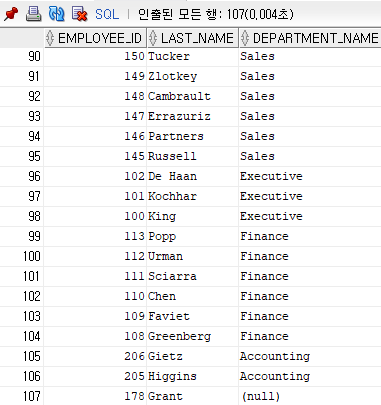
▶ 맨 밑에 null까지 출력된 걸 볼 수 있다.
ex 2)
select e.employee_id, e.last_name, d.department_name
from hr.employees e, hr.departments d
where e.department_id(+) = d.department_id;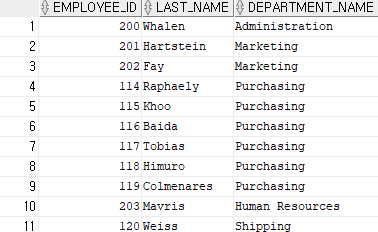
▶ employee 테이블에 존재하는 모든 직원(e.department_id)을 포함시키고, 그 직원이 속한 부서가 없는 경우에도 직원 정보 표시. 반면 departments 테이블에 부서 정보가 없는 경우 해당 행은 NULL로 처리
ex 3) 전부 출력하고 싶을 경우
select e.employee_id, e.last_name, d.department_name, l.city
from hr.employees e, hr.departments d, hr.locations l
where e.department_id = d.department_id(+)
and d.location_id = l.location_id(+);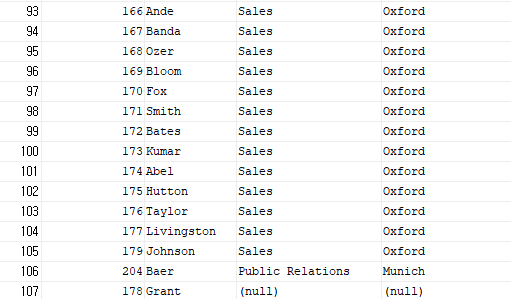
2. self join
- 자신의 테이블을 참조할 때 사용하는 조인
- 테이블 별칭으로 구분해서 해줄 것 (같게 하면 모호성으로 오류 발생함)
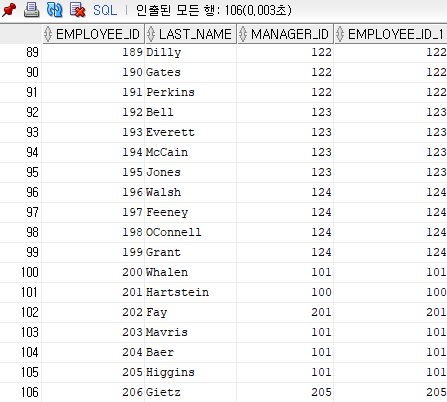
ex) 사원들의 관리자(직속상관) 정보를 파악해 주세요.
select w.employee_id, w.last_name, w.manager_id, m.employee_id
from hr.employees m, hr.employees w
where w.manager_id = m.employee_id;▶ 하지만 데이터가 하나 누락되어있다. 회사의 CEO king은 null값으로 들어가 있기 때문에 누락이 되어있다.
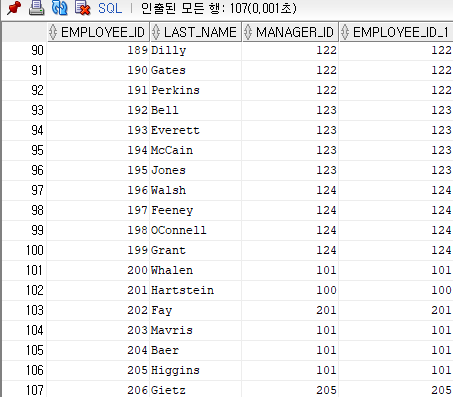
select w.employee_id, w.last_name, w.manager_id, m.employee_id
from hr.employees m, hr.employees w
where w.manager_id = m.employee_id(+);▶ king의 manager_id가 null값이라 누락이 되가지고 없으니 출력하려면 반대쪽 m.employee_id에 (+)를 붙인다.
3. non equi join
- equi join(=) 할 수 없는 다른 비교연산자를 사용하는 조인 기법
- 값을 범위로 조인하려는 경우 많이 사용한다.
- 범위를 찾을 때 사용하면 된다.
- <, <=, >, >=, !=, between and 사용 가능
ex) 사원들의 급여가 어느 범위에 속하는지 알고 싶을 때
select e.employee_id, e.salary, j.grade_level
from hr.employees e, hr.job_grades j
where e.salary >= j.lowest_sal
and e.salary <= j.highest_sal;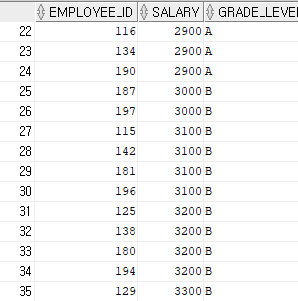
문제) 사원들의 employee_id, salary, grade_level, department_name, city 정보를 출력하시오. 부서배치를 받지 않은 사원도 포함시켜 주세요.
select e.employee_id, e.salary, j.grade_level, d.department_name, l.city
from hr.employees e, hr.departments d, hr.job_grades j, hr.locations l
where e.salary between j.lowest_sal and j.highest_sal
and e.department_id = d.department_id(+)
and d.location_id = l.location_id(+);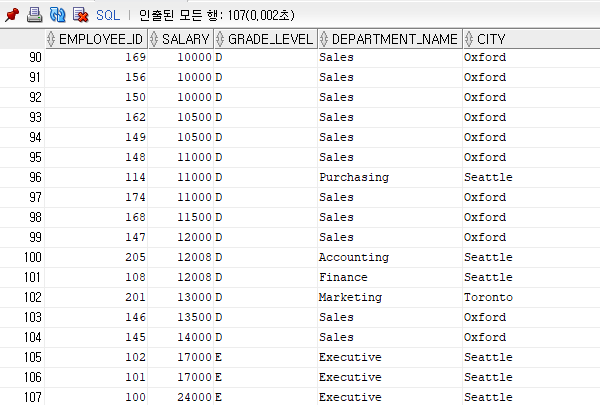
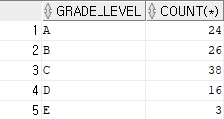
문제 2) 사원들의 급여 등급 레이블의 빈도수를 출력해 주세요.
select j.grade_level,count(*)
from hr.employees e, hr.job_grades j
where e.salary >= j.lowest_sal
and e.salary <= j.highest_sal
group by j.grade_level
order by 1;▶ 빈도수이기 때문에 count를 써주고, count는 그룹함수이기 때문에 그 외 컬럼을 group by를 해줘야 한다.
▶ order by절을 통해 알파벳 순으로 정렬해 준다.
■ ANSI-SQL JOIN 문법 (지금까진 오라클 전용)
1. natural join (현장에선 안 쓰고 회사에서 쓰지 말라고 하는 곳도 있음 ex) 같은 department_id여도 서로 같고 있는 의미가 다르기 때문에 안 쓰는 게 좋다.)
- equi join
- 조인조건 술어를 자동으로 생성한다.
- 양쪽 테이블의 동일한 이름의 모든 컬럼을 기준으로 조인조건 술어를 만들어준다.
ex 1) 오라클인 경우
select e.employee_id, d.department_name
from hr.employees e, hr.departments d
where e.department_id = d.department_id --조인조건 술어
and e.manager_id = d.manager_id; -- 조인조건 술어ex 1) natural join을 쓸 경우
select e.employee_id, d.department_name
from hr.employees e natural join hr.departments d;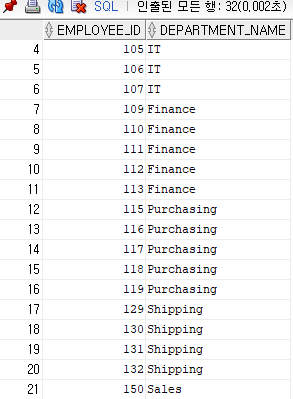
▶ 출력값은 같다.
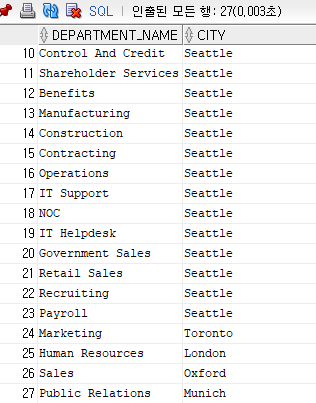
ex 2) natural join 이용
select department_name, city
from hr.departments natural join hr.locations;ex 2) oracle 이용
select department_name, city
from hr.departments d, hr.locations l
where d.location_id = l.location_id;
2. join using
- equi join
- 조인조건의 컬럼을 지정한다.
- using절에 사용된 기준 컬럼은 어느 테이블이라고 지정하면 오류발생 (컬럼 이름 그대로 써야 함)
- using의 역할 : 두 개의 테이블이 내부 조인으로 조인될 때, 조인하고자 하는 두 테이블의 컬럼명이 같을 경우 조인 조건을 길게 적지 않고 간단하게 적을 수 있도록 하는 역할
- using(x)의 x에는 조인하는 테이블의 컬럼명이 같아야 한다. (데이터가 교집합 되더라도, 컬럼명이 다르면 인식 불가)
ex 1) 양쪽 테이블에 using(department_id)컬럼을 기준으로 join 해줄 경우
select e.employee_id, d.department_name
from hr.employees e join hr.departments d
using(department_id);
ex 2) 3개의 테이블로 할 경우
select e.employee_id, department_name, l.city
from hr.employees e join hr.departments d
using(department_id)
join hr.locations l
using(location_id)
where department_id = 20;▶부서 id가 20인 직원들이 id, 부서명, 그리고 해당 부서가 위치한 도시 이름을 조회하는 쿼리이다.

3. join on = inner join on
- equi join
- on 절을 이용해서 조인조건 술어를 직접 만들어서 사용한다.
- 회사마다 inner join on, join on 다르니 당황하지 말고 사용하기
ex 1)
select e.employee_id, d.department_name
from hr.employees e join hr.departments d
on e.department_id = d.department_id
join hr.locations l
on d.location_id = l.location_id;↕
select e.employee_id, d.department_name
from hr.employees e inner join hr.departments d
on e.department_id = d.department_id
inner join hr.locations l
on d.location_id = l.location_id;
ex 2)
select w.employee_id, w.last_name, w.manager_id, m.employee_id
from hr.employees m join hr.employees w
on w.manager_id = m.employee_id;↕
select w.employee_id, w.last_name, w.manager_id, m.employee_id
from hr.employees m inner join hr.employees w
on w.manager_id = m.employee_id;
ex 3)
select e.employee_id, e.salary, j.grade_level
from hr.employees e join hr.job_grades j
on e.salary between j.lowest_sal and j.highest_sal;↕
select e.employee_id, e.salary, j.grade_level
from hr.employees e inner join hr.job_grades j
on e.salary between j.lowest_sal and j.highest_sal;
4. outer join
- 키값이 일치되는 데이터 또는 키값이 일치되지 않은 데이터도 출력하는 조인
- 한쪽에만 (+) 표현한다.
- 양쪽에 (+)를 수행하면 오류 발생
- outer join의 종류
ex) A 테이블의 a 컬럼의 값이 10,20,30이고
B 테이블의 a 컬럼의 값이 10,20,30,40일 때
- right outer join : 교집합 되지 않았던 B테이블의 a컬럼의 값이 40인 데이터도 가져올 수 있다.
select a,b,c,d,e,f,k
from A, B
where A.a(+) = B.a; --(right 조인이면 +부호를 왼쪽에!!)ex) ANSI JOIN (표준화)
select a,b,c,d,e,f,k
from A right outer join B
on A.a = B.a;▶ 이렇게 right outer join을 하면 교집합 되지 않은 B에 있는 데이터를 추가로 가져오겠단 의미이다.
▶ A, B INNER JOIN + B에 있는 데이터
- left outer join : 왼쪽 테이블에 있는 데이터를 추가로 가져온다.
ex) oracle join
select a,b,c,d,e,f,k
from A, B
on A.a = B.a(+) -- left join이면 +부호를 오른쪽에!!)
ex) ANSI JOIN (표준화)
select a,b,c,d,e,f,k
from A left outer join B
on A.a = B.a;▶ 교집합 되지 않은 A에 있는 데이터를 추가로 가져오겠다는 의미이다.
▶ A, B INNER JOIN +A에 있는 데이터
- full outer join : 한 마디로 제한 없이 모든 데이터를 가져올 수 있다.
select a,b,c,d,e,f,k
from A full outer join B
on A.a = B.a;▶ 보통 join을 사용하는 이유는 중복되는 값을 가져오기 위해서인데 full outer join은 모든 데이터를 가져오다 보니 사용빈도가 많지 않다.
★ 주의사항 : INNER JOIN은 null 값이 있는 경우 처리하지 못해서 null 값은 제외되지만, OUTER JOIN은 null 값을 포함해서 가져온다.
ex ) oracle
select e.employee_id, d.department_name, l.city
from hr.employees e, hr.departments d, hr.locations l
where e.department_id = d.department_id(+)
and d.location_id = l.location_id(+);
ex) ANSI 표준화
select e.employee_id, d.department_name, l.city
from hr.employees e left outer join hr.departments d
on e.department_id = d.department_id
left outer join hr.locations l
on d.location_id = l.location_id;▶ 둘 다 결과는 같다. oracle where절 보면 +부호가 오른쪽이기 때문에 반대인 LEFT OUTER JOIN을 해줘야 한다.
▶ 먼저 department_id 끼리 비교해 주고 (순서 바뀌어도 됨), 그 결과값이랑 hr.location이랑 비교해줘야 하므로 LEFT OUTER JOIN을 한 번 더 해준다.
문제 1) 2006년도에 입사한 사원들의 부서이름별 급여의 총액, 평균을 출력하시오.
1. oracle 방법
select d.department_name, sum(e.salary),avg(e.salary)
from hr.employees e, hr.departments d
where hire_date >= to_date('2006-01-01', 'yyyy-mm-dd')
and hire_date < to_date('2007-01-01', 'yyyy-mm-dd')
and e.department_id = d.department_id
group by d.department_name;
2. ANSI 표준 방법
select d.department_name, sum(e.salary),avg(e.salary)
from hr.employees e join hr.departments d
on e.department_id = d.department_id
where hire_date >= to_date('2006-01-01', 'yyyy-mm-dd')
and hire_date < to_date('2007-01-01', 'yyyy-mm-dd')
group by d.department_name;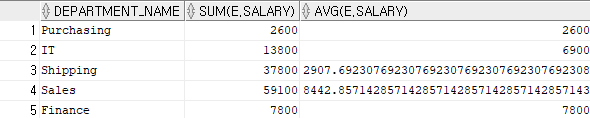
문제 2) 사원들의 last_name, salary, grade_level, department_name을 출력하는데 last_name에 a문자가 2개 이상 포함되어 있는 사원들을 출력하시오.
1. oracle 방법
select e.last_name, e.salary, j.grade_level, d.department_name
from hr.employees e, hr.departments d, hr.job_grades j
where last_name like '%a%a%'
and e.salary between j.lowest_sal and j.highest_sal
and e.department_id = d.department_id;
2. ANSI 표준화 방법
select e.last_name, e.salary, j.grade_level, d.department_name
from hr.employees e inner join hr.departments d
on e.department_id = d.department_id
join hr.job_grades j
on e.salary between j.lowest_sal and j.highest_sal
where last_name like '%a%a%';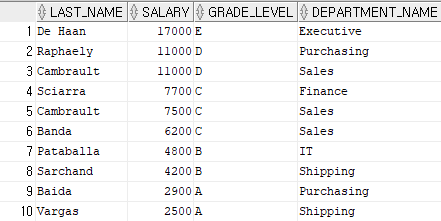
5. cartesian product (카션 곱)
- 조인조건이 생략된 경우
- 조인조건이 잘못 생성된 경우
- 첫 번째 테이블 행의 수와 두 번째 테이블의 행 수가 곱해진다.
select employee_id, department_name
from hr.employees, hr.departments;select employee_id, department_name
from hr.employees cross join hr.departments;▶ 둘 다 결과는 같다.
▶ 일부러 카티션 곱을 유발시키는 것
▶ 카티션 곱 JOIN이 일어나게 되면 from 절에서 참조한 테이블들의 행 개수를 각각 모두 곱한 만큼의 결과가 출력
1) 카티션곱 활용방법
- 키를 이용하지 않고 그냥 모든 데이터를 1:1로 연결하는 join 방법
- 실무에서 자주 쓰지 않지만 간혹 필요할 때가 있음
- 데이터를 대량으로 복제해야 할 때
- 특정 데이터 튜플만 복제되어야 할 때
- 연결고리가 없는 두 테이블의 데이터를 무작위로 합쳐야 할 때 등
'oracle SQL' 카테고리의 다른 글
| 2024.12.06 8일차 수업 (0) | 2024.12.06 |
|---|---|
| 2024.12.05 7일차 수업 (2) | 2024.12.05 |
| 2024.12.03 5일차 수업 (2) | 2024.12.03 |
| 2024.12.02 4일차 수업 (4) | 2024.12.02 |
| 2024.11.29 3일차 수업 (0) | 2024.11.29 |



