문제) 부서별 최고 급여를 받는 사원들의 정보를 출력해 주세요.
1. correlate subquery 이용
내 답)
select *
from hr.employees e
where salary in (select max(salary)
from hr.employees
where department_id = e.department_id)
order by e.department_id;
교수님 답)
select *
from hr.employees e
where salary = (select max(salary)
from hr.employees
where department_id = e.department_id);
2. inline view 이용
select e2.*
from (select department_id, max(salary) max_sal
from hr.employees
group by department_id) e1, hr.employees e2
where e1.department_id = e2.department_id
and e2.salary = e1.max_sal;
■ exists 연산자 ★★
- 후보행값이 서브쿼리에 존재하는지 여부를 찾는 연산자
- 후보행값이 서브쿼리에 존재하면 true, 우리가 찾는 데이터 검색 종료
- 후보행값이 서브쿼리에 존재하지 않으면 false, 우리가 찾는 데이터가 아니다. (버려야 될 데이터)
- 기준 컬럼을 쓰면 안 되고 서브쿼리 내에 select절에 문법 오류만 안 나게 문자를 적는다. (보편적으로 'x'를 많이 쓴다.)
ex) 기존방식
select *
from hr.employees
where employee_id in (select /*+no_unnest */ manager_id
from hr.employees);
ex) 변형 (이렇게 쓰는 습관을 갖는 게 좋다.)
select *
from hr.employees
where exists (select 'x'
from hr.employees
where manager_id = e.employee_id);▶ 서브쿼리가 먼저 실행하지 않고 메인쿼리가 먼저 실행된다. 그 이유는 where절에 e.employee_id가 있기 때문이다.
# 관리자가 아닌 사원을 출력하시오.
1. not in 사용
select *
from hr.employees
where employee_id not in (select /*+no_unnest */ manager_id
from hr.employees
where manager_id is not null);
2. not exists 사용
select *
from hr.employees e
where not exists (select 'x'
from hr.employees
where manager_id = e.employee_id);
■ not exists 연산자 ★★
- 후보행이 서브쿼리에 존재하지 않으면 데이터를 찾는 연산자
- 후보행값이 서브쿼리에 존재하지 않으면 true, 우리가 찾는 데이터
- 후보행값이 서브쿼리에 존재하면 false, 우리가 찾는 데이터가 아니다. 검색 종료
ex)
select *
from hr.employees e
where not exists (select 'x'
from hr.employees
where manager_id = e.employee_id);문제 1) 소속 사원이 있는 부서 정보를 출력해 주세요.
1. in 사용
select *
from hr.departments
where department_id in (select department_id
from hr.departments);2. exists 사용
select *
from hr.departments
where exists (select 'x'
from hr.departments);
문제 2) 소속 사원이 없는 부서 정보를 출력해 주세요.
1. not in 사용
select *
from hr.departments
where department_id not in (select department_id
from hr.employees
where department_id is not null);
2. not exists 사용
select *
from hr.departments d
where not exists (select 'x'
from hr.employees
where department_id = d.department_id);
문제 3) 사원들의 급여 등급에 포함된 등급정보를 출력해 주세요.
1. in 사용
select *
from job_grades
where grade_level in (select j.grade_level
from hr.job_grades j, hr.employees e
where e.salary between j.lowest_sal and j.highest_sal);▶ 이 코드의 문제점은 hr.job_grades라는 테이블을 2번 엑세스하기 때문에 성능적으로 좋진 않다.
2. exists 사용
select *
from job_grades j
where exists (select 1
from hr.employees
where salary between j.lowest_sal and j.highest_sal);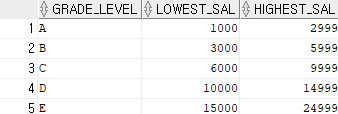
문제 4) 사원들의 급여 등급에 포함되지 않은 등급정보를 출력해 주세요.
1. not in 사용
select *
from job_grades
where grade_level not in(select grade_level
from hr.job_grades j, hr.employees e
where e.salary between j.lowest_sal and j.highest_sal);▶ 서브쿼리절에 null값이 없기 때문에 (급여를 0원 받는 사원은 없을 거기 때문에 밑에 null을 안 적어도 된다.) 정상 작동이 된다.
2. not exists 사용
select *
from job_grades j
where not exists(select 'x'
from hr.employees
where salary between j.lowest_sal and j.highest_sal);
ex)
select department_id, count(*)
from hr.employees
group by department_id;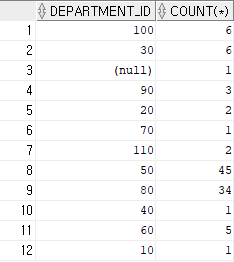
▶ 부서 id별로 출력하는 건 문제가 되지 않는다.
▶ 하지만 가끔 열별로 출력해 달라고 하는 경우가 있다.
# 그럴 땐 DECODE 함수로 쓸 순 있다.
select
count(decode(department_id, 10, 'x')) "10",
count(decode(department_id, 20, 'x')) "20",
count(decode(department_id, 30, 'x')) "30",
count(decode(department_id, 40, 'x')) "40",
count(decode(department_id, 50, 'x')) "50",
count(decode(department_id, 60, 'x')) "60",
count(decode(department_id, 70, 'x')) "70",
count(decode(department_id, 80, 'x')) "80",
count(decode(department_id, 90, 'x')) "90",
count(decode(department_id, 100, 'x')) "100",
count(decode(department_id, 110, 'x')) "110",
count(decode(department_id, null, '부서x')) "부서X"
from hr.employees;▶ DECODE 함수는 하나의 행마다 12번 비교해야 되기 때문에 107 *12번 해야 해서 좋지 않은 방법이다.
▶ 예를 들어 department_id가 60이 들어왔다고 가정하면 맨 위에 10부터 쭉 비교한다.
▶ 그러다 같은 60을 만나면 카운트가 되고 끝나는 게 아니라 맨 밑에 null까지 다 비교하고 끝낸다.
# 더 좋은 방법은 인라인 뷰를 이용해서 푸는 방법
select
decode(department_id, 10, cnt) "10",
decode(department_id, 20, cnt) "20",
decode(department_id, 30, cnt) "30",
decode(department_id, 40, cnt) "40",
decode(department_id, 50, cnt) "50",
decode(department_id, 60, cnt) "60",
decode(department_id, 70, cnt) "70",
decode(department_id, 80, cnt) "80",
decode(department_id, 90, cnt) "90",
decode(department_id, 100, cnt) "100",
decode(department_id, 110, cnt) "110",
decode(department_id, null, cnt) "부서X"
from (select department_id, count(*) cnt
from hr.employees
group by department_id);▶ 인라인 뷰를 만들어 부서ID 별로 카운트를 세주고, 그 결과 집합으로 decode를 돌리면 CPU를 적게 쓴다.
▶ 12 * 12 돌아간다.

# 하지만 12 * 12 줄로 되어있어서 한 줄로 나타내고 싶을 경우
select
max(decode(department_id, 10, cnt)) "10",
max(decode(department_id, 20, cnt)) "20",
max(decode(department_id, 30, cnt)) "30",
max(decode(department_id, 40, cnt)) "40",
max(decode(department_id, 50, cnt)) "50",
max(decode(department_id, 60, cnt)) "60",
max(decode(department_id, 70, cnt)) "70",
max(decode(department_id, 80, cnt)) "80",
max(decode(department_id, 90, cnt)) "90",
max(decode(department_id, 100, cnt)) "100",
max(decode(department_id, 110, cnt)) "110",
max(decode(department_id, null, cnt)) "부서X"
from (select department_id, count(*) cnt
from hr.employees
group by department_id);▶ 여러 행을 하나의 행으로 합치는 그룹함수(max, min, count등)를 쓰면 해결이 된다.
▶ 문제점 : DECODE가 너무 많고 코드도 길어진다.

# 위에를 해결하기 위한 함수
■ pivot 함수
- 행(세로) 데이터를 열(가로)로 변경하는 함수
- pivot 함수 안에는 첫 번째로 무조건 그룹함수가 들어가야 한다.
- 컬럼에 별칭을 쓰고 싶을 땐 한 칸 띄고, as나 큰 따옴표로 쓰면 된다.
- for x in 사이에 x는 인라인 뷰 안에 제한하는 컬럼을 적어준다. (별칭도 가능)
ex 1)
select *
from (select department_id
from hr.employees)
pivot(count(*) for department_id in(10 as "10번 부서",20,30,40,50,60,70,80,90,100,110,null "부서x"));
▶ 별칭을 넣고 싶을 땐 as를 쓰거나 한 칸 띄고 큰 따옴표로 별칭을 지정할 수 있다.
ex 2) 부서 id별로 총액을 알고 싶을 경우
select *
from (select department_id, salary
from hr.employees)
pivot(sum(salary) for department_id in (10,20,30,40,50,60,70,80,90,100,110,null "부서x"));
문제 1) 연도별 입사 인원수를 가로 방향으로 출력해 주세요.
정답 1 -
select *
from (select to_char(hire_date, 'yyyy') year
from hr.employees)
pivot(count(*) for year in (2001,2002,2003,2004,2005,2006,2007,2008));
정답 2 -
select *
from(select to_char(hire_date, 'yyyy') year, count(*) cnt
from hr.employees
group by to_char(hire_date, 'yyyy'))
pivot(max(cnt) for year in (2001,2002,2003,2004,2005,2006,2007,2008));▶ pivot 안에 첫 번째로 무조건 그룹함수를 써야 하지만 값이 변하지 않는 그룹함수를 써줘야 한다. 만약 count를 적게 되면 그 행의 데이터의 카운트 개수를 출력해서 1이 나오기 때문에 count를 제외한 그룹함수를 적어줘야 한다.
ex) 총 인원수하고 총급여까지 구하고 싶을 때
select *
from(select to_char(hire_date, 'yyyy') year, count(*) cnt
from hr.employees
group by to_char(hire_date, 'yyyy'))
pivot(min(cnt) for year in(2001,2002,2003,2004,2005,2006,2007,2008)),
(select count(*) 총인원수
from hr.employees),
(select to_char(sum(salary), 'l999,999')총액
from hr.employees);▶ 밑에 인라인 뷰를 하나 더 만들면 되고 더 구하고 싶으면 계속 밑에다 인라인 뷰를 만들면 된다. (pivot 함수 하고는 별개로 인라인 뷰를 만드는 것)
■ unpivot 함수
- 열(가로)을 행(세로)으로 변경하는 함수
select *
from ( 피벗 대상 쿼리문)
unpivot( 컬럼별칭(값) for 컬럼별칭(열) in (피벗열명 as '별칭', ....)▶ 컬럼별칭(값) : unpivot을 할 때 열의 값을 표시할 컬럼명을 지정하는 부분이다. 사용자가 임의로 별칭 지정 가능
▶ 컬럼별칭(열) : unpivot을 할 때 열의 컬럼명이 행으로 표시될 때 해당 컬럼의 별칭이다.
▶ 피벗열명 : unpivot 대상 컬럼명을 지정하면 된다. 별칭을 지정할 때는 문자열(")로 부여하면된다.
▶ 주의할 점 : 피벗열명 적을 때 숫자형으로 적으면 에러 뜬다. 그 이유는 피벗열명이 컬럼으로 들어가게 되는데 컬럼은 문자형으로 되어있기 때문에 숫자형인 데이터가 들어가면 에러가 발생한다.
select *
from(select *
from(select to_char(hire_date, 'yyyy') year, count(*) cnt
from hr.employees
group by to_char(hire_date, 'yyyy'))
pivot(max(cnt) for year in (2001,2002,2003,2004,2005,2006,2007,2008)))
unpivot(인원수 for 년도 in ("2001","2002","2003","2004","2005","2006","2007","2008"));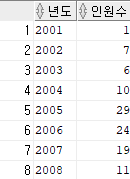
'oracle SQL' 카테고리의 다른 글
| 2024.12.10 10일차 수업 (2) | 2024.12.10 |
|---|---|
| 2024.12.09 9일차 수업 (2) | 2024.12.09 |
| 2024.12.05 7일차 수업 (2) | 2024.12.05 |
| 2024.12.04 6일차 수업 (0) | 2024.12.04 |
| 2024.12.03 5일차 수업 (2) | 2024.12.03 |



