# 집합연산자의 활용
ex 1) union 사용
select e.employee_id, d.department_name
from hr.employees e, hr.departments d -> 키값이 일치되는 값을 뽑아내고 사원테이블을 뽑는다.
where e.department_id = d.department_id(+)
union
select e.employee_id, d.department_name
from hr.employees e, hr.departments d
where e.department_id(+) = d.department_id; -> 키값이 일치되는 값을 뽑아내고 부서테이블 뽑는다.
ex 2) union -> union all + not exists (바꿀 때 같이 생각하기)
# 위에 거를 성능이 좋게 가공할 때
select e.employee_id, d.department_name
from hr.employees e, hr.departments d
where e.department_id = d.department_id(+)
union all
select null, department_name
from hr.departments d
where not exists (select 'x'
from hr.employees
where department_id = d.department_id);
ex 3) full outer join 사용
select e.employee_id, d.department_name
from hr.employees e full outer join hr.departments d
on e.department_id = d.department_id;
▶ 키값이 일치하는 것과 일치하지 않은 것도 다 뽑아낼 땐 full outer join을 쓰는 게 좋다.
▶ 테이블을 한 번만 엑세스하기 때문에 성능적으로도 좋다.
[문제]
1) department_id, job_id, manager_id 기준으로 총액 급여를 출력
select department_id, job_id, manager_id, sum(salary)
from hr.employees
group by department_id, job_id, manager_id;
2) department_id, job_id 기준으로 총액 급여를 출력
select department_id, job_id, sum(salary)
from hr.employees
group by department_id, job_id;
3) department_id 기준으로 총액 급여를 출력
select department_id, sum(salary)
from hr.employees
group by department_id;
4) 전체 총액 급여를 출력
select sum(salary)
from hr.employees;
5) 1,2,3,4번을 한꺼번에 출력하시오
select department_id, job_id, manager_id, sum(salary)
from hr.employees
group by department_id, job_id, manager_id
union all
select department_id, job_id, null, sum(salary)
from hr.employees
group by department_id, job_id
union all
select department_id,null,null, sum(salary)
from hr.employees
group by department_id
union all
select null, null, null, sum(salary)
from hr.employees;▶ 동일한 테이블을 4번 엑세스하고 있기 때문에 성능적으로 안 좋다.

■ rollup(8i)
- group by절에 지정된 열 리스트를 오른쪽에서 왼쪽 방향으로 이동하면서 그룹화를 만드는 연산자
- group by절에만 같이 쓰는 함수이다.
- ex) sum(sal) = {a, b, c}
sum(sal) = {a,b}
sum(sal) = {a}
sum(sal) = {}
# 위에 거를 rollup을 이용해 쉽게 바꾸는 방법
select department_id, job_id, manager_id, sum(salary)
from hr.employees
group by rollup(department_id, job_id, manager_id);▶ sum(sal) = {department_id, job_id, manager_id}
sum(sal) = {department_id, job_id}
sum(sal) = {department_id}
sum(sal) = {}
■ cube 연산자(8i)
- rollup 연산자를 포함하고 모든 그룹화 할 수 있는 걸 만드는 연산자
- ex) sum(sal) = {a,b,c}
sum(sal) = {a,b}
sum(sal) = {a,c}
sum(sal) = {b,c}
sum(sal) = {a}
sum(sal) = {b}
sum(sal) = {c}
sum(sal) = {}
select department_id, job_id, manager_id, sum(salary)
from hr.employees
group by cube(department_id, job_id, manager_id);▶ sum(sal) = {department_id, job_id, manager_id}
sum(sal) = {department_id, job_id}
sum(sal) = {department_id, manager_id}
sum(sal) = {job_id, manager_id}
sum(sal) = {job_id}
sum(sal) = {department_id}
sum(sal) = {manager_id}
sum(sal) = {}
■ grouping sets 연산자(9i)
- 내가 원하는 그룹을 만드는 연산자
- select a, b, c, sum(sal)
from test
group by grouping sets((a,b), (a, c), ());
-> () : 전체를 의미
ex)
select department_id, job_id, manager_id, sum(salary)
from hr.employees
group by grouping sets((department_id, job_id),(department_id,manager_id),());▶ sum(sal) = {department_id, job_id}
sum(sal) = {department_id,manager_id}
sum(sal) = {}
문제) 년도, 분기별 총액을 구하시오. (행과 열의 합도 구하시오)
1)
select year 년도,
max(decode(quarter, 1, sum_sal)) "1분기",
max(decode(quarter, 2, sum_sal)) "2분기",
max(decode(quarter, 3, sum_sal)) "3분기",
max(decode(quarter, 4, sum_sal)) "4분기",
max(decode(quarter, null, sum_sal)) "합"
from(select to_char(hire_date, 'yyyy') year,
to_char(hire_date, 'q') quarter,
sum(salary) sum_sal
from hr.employees
group by cube(to_char(hire_date, 'yyyy'),
to_char(hire_date, 'q')))
group by year
order by 1;
2)
select *
from(select year, nvl(quarter, 0) quarter, sum_sal
from(select to_char(hire_date, 'yyyy') year,
to_char(hire_date, 'q') quarter,
sum(salary) sum_sal
from hr.employees
group by cube(to_char(hire_date, 'yyyy'),to_char(hire_date, 'q'))))
pivot(max(sum_sal) for quarter in (1 "1분기",2 "2분기",3 "3분기",4 "4분기",0 "합"))
order by 1;▶ pivot 함수에 지정 받지 않은 컬럼은 기준 컬럼이 된다.
▶ 현재 pivot 함수 안에 quater 별로 컬럼을 정했기 때문에 year가 기준 컬럼이 된다.

■ 계층검색 (Hierarchical Query)
ex) 위에서 밑으로 하는 방식 (prior)
select employee_id, last_name, manager_id
from hr.employees
start with employee_id = 101 --시작점, 시작해야 할 조건 생성
connect by prior employee_id = manager_id; -- 연결고리 조건▶ prior는 전 단계 사원의 employee_id를 manager_id로 삼고 있는 것을 출력

ex) 밑에서 위로 방식 (prior)
select employee_id, last_name, manager_id
from hr.employees
start with employee_id = 101
connect by employee_id = prior manager_id;▶ prior를 어디두냐에 따라 출력값이 달라진다.
# 의사열(pseudo column) : 실제 존재하지 않은 컬럼인데 마치 있는 컬럼처럼 사용하는 컬럼
select level, employee_id, last_name, manager_id
from hr.employees
start with employee_id = 105
connect by employee_id = prior manager_id;
# 계층 구조에 따라 들여 쓰기와 함께 해당 직원의 last_name을 반환한다.
select level, lpad(' ', level*2 -2, ' ') ||last_name
from hr.employees
start with employee_id = 100
connect by prior employee_id = manager_id;
- order siblings by : 계층 검색에서 정렬 수행 시 필수로 입력해야 하는 함수 (계층이 망가지지 않게 정렬을 해준다.)
- 위치표기법, 별칭 불가능
ex)
select level, lpad(' ', level*2 -2, ' ') ||last_name
from hr.employees
start with employee_id = 100
connect by prior employee_id = manager_id
order siblings by last_name;
# 같은 코드를 작성해도 제한을 어디다 하냐에 따라 값이 정말 달라진다.
- 101번 사원은 뽑고 싶지 않을 경우
1) where 절에 썼을 경우
select level, lpad(' ', level*2 -2, ' ') ||last_name
from hr.employees
where employee_id != 101
start with employee_id = 100
connect by prior employee_id = manager_id
order siblings by last_name;▶ where절은 행을 제한하기 때문에 101번 사원만 없어진다.

2) connect by절 밑에 and로 쓸 경우
select level, lpad(' ', level*2 -2, ' ') ||last_name
from hr.employees
start with employee_id = 100
connect by prior employee_id = manager_id
and employee_id != 101
order siblings by last_name;▶ connect by 밑에 and로 쓰면 101번과 연결된 조직 전부가 삭제된다 생각하면 되니 주의해야 한다.

문제 1) select문을 이용해서 1~100 출력해 주세요.
select level
from dual
connect by level <= 100;
문제 2) select문을 이용해서 2단을 출력해 주세요.
select '2 * '||level|| ' = '|| 2*level "2단"
from dual
connect by level <= 9;
문제 3) 2~9단까지 출력해 주세요.
내 답 :
select '2 * ' ||level||' = '|| 2*level "2단",
'3 * ' ||level||' = '|| 3*level "3단",
'4 * ' ||level||' = '|| 4*level "4단",
'5 * ' ||level||' = '|| 5*level "5단",
'6 * ' ||level||' = '|| 6*level "6단",
'7 * ' ||level||' = '|| 7*level "7단",
'8 * ' ||level||' = '|| 8*level "8단",
'9 * ' ||level||' = '|| 9*level "9단"
from dual
connect by level <= 9;
강사님 답 : 카디션 곱을 의도적으로 유발
select dan || '*'|| num ||' = '|| dan * num "2~9단"
from(select level + 1 dan
from dual
connect by level <= 8),
(select level num
from dual
connect by level <= 9);
■ DDL (Data Definition Language)
- CREATE
- ALTER
- DROP
- TRUNCATE
- RENAME
- COMMENT
■ 유저 관리
1. 권한 (privilege)
- 특정한 SQL문을 수행할 수 있는 권리 (면접 때 많이 물어봄!!)
- 시스템 권한 : DB에 영향을 줄 수 있는 권한
- 객체 권한 : 객체(테이블)를 사용할 수 있는 권한
- ROLE(롤) : 유저에게 부여할 수 있는 권한을 모아 놓은 객체, 유저 관리에 대한 편리성
# 내가 받은 객체 권한을 확인
select * from user_tab_privs;
# 내가 받은 ROLE 권한을 확인
select * from session_roles;
# 새션한 사용자 시스템 권한 확인 (밑에 2개를 union한 값)
select * from session_privs;
# 유저가 받은 시스템 권한 확인
select * from role_sys_privs;
# 유저에게 직접 부여한 시스템 권한 확인 (일단 코드만 외우기)
select * from user_sys_privs;
■ 테이블 생성
# 테이블을 생성하려면 2가지를 체크해야 한다.
1) 테이블을 생성할 수 있는 시스템 권한이 있는지 체크 (create table)
2) 테이블을 저장할 수 있는 테이블스페이스 확인(권한)
ex 1) UNLIMITED TABLESPACE : 모든 테이블스페이스를 사용할 수 있는 권한
ex 2) select * from user_ts_quotas; -> 특정한 테이블스페이스를 사용할 수 있는 권한
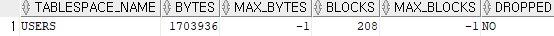
■ 테이블 이름, 컬럼 이름, 유저 이름, 다른 객체 이름, 제약조건 이름
- 문자로 시작한다.
- 문자 길이는 1~30까지 가능하다.
- 문자, 숫자, 특수문자(_, $, #) 가능하다.
- 대소문자 구분하지 않는다.
- 동일한 유저가 소유한 객체 이름은 중복되면 안 된다.
- 소유자가 다를 경우 객체 이름 동일하게 만들어도 된다.
ex) hr.employees, scott.employees
- 예약어는 사용할 수 없다.
1) 보는 방법
select * from v$reserved_words;
▶ hr에서 하면 에러가 뜨고 DBA 섹션에서 확인해야 한다.
desc hr.employees;
# 컬럼 타입
- number(p, s) : 가변(자기가 사용한 만큼) 길이 숫자 타입, p : 전체 자릿수, s : 소수점 자릿수
- varchar2(4000) : 가변길이 문자 타입 (최대 길이 4000)
- char(2000) : 고정 길이 문자 타입
- date : 날짜 타입
- clob : 가변 길이 문자 타입, 최대 4기가 입력 가능
- blob : 가변 길이 이진 데이터(이미지, 소리 등) 타입, 최대 4기가 입력 가능
- bfile : 외부파일에 저장된 이진 데이터 타입, 최대 4기가 입력 가능
# 내가 생성한 테이블, 뷰 확인하는 법
select * from tab;
■ 유저 생성 (유저 생성할 수 있는 권한은 DBA밖에 없다.)
- sys 계정에서 물리/논리적인 저장공간을 확인하는 방법
select * from dba_data_files;
- 임시저장소(temporany) 디스크용량 확인 방법
select * from dba_temp_files;
- 테이블스페이스 확인하는 법
select * from dba_tablespaces;
# insa라는 유저 이름으로 유저 생성
create user insa
identified by oracle
default tablespace users
temporary tablespace temp
quota 10m on users;▶ 만약 똑같은 유저로 만들게 되면 오류가 뜬다. (고유 이름으로 해줄 것)
▶ default tablespace users : 아무 땅에다 집을 지으면 안되니 tablespace는 책장과 같다. 업무 특성으로 나눈다.
▶ temporary tablespace temp : 임시저장소는 temp
▶ quota 10m on users : 땅을 할당함, users라는 tablespace에서 10Mbyte 정도 사용할 수 있게 한다.
■ 유저 삭제 (DBA)
drop user insa cascade;▶ cascade는 먼저 오브젝트를 먼저 삭제한 후 insa 유저를 삭제한다.

■ 권한 관리 (DBA)
- DCL (Data Control Language)
1) grant (로그인을 할 수 있는 권한 부여)
grant create session to insa;
# 제대로 부여했는지 확인하는 방법
select * from dba_sys_privs where grantee = 'INSA';
# 권한 전

# 권한 후

2) revoke (권한 회수)
# 시스템 권한 회수
revoke create session from insa;
# 회수됐는지 확인하는 법
select * from dba_sys_privs where grantee = 'INSA';
▶ 회수되가지고 비어있는 걸 볼 수 있다.
'oracle SQL' 카테고리의 다른 글
| 2024.12.12 12일차 수업 (2) | 2024.12.12 |
|---|---|
| 2024.12.11 11일차 수업 (0) | 2024.12.11 |
| 2024.12.09 9일차 수업 (2) | 2024.12.09 |
| 2024.12.06 8일차 수업 (0) | 2024.12.06 |
| 2024.12.05 7일차 수업 (2) | 2024.12.05 |



