■ 테이블 복제 (CTAS 용어 꼭 알기!)
- 테이블 구조, 행(데이터), 제약 조건 중에 NOT NULL 복제된다.
ex 1)
drop table hr.emp purge;
create table hr.emp
as
select * from hr.employees;
select * from hr.emp;
▶ hr.employees에 있는 사원정보를 emp 테이블에 이관하는 작업이다.
♣ group by절에는 서브쿼리를 쓰지 않는다.
ex 2)
drop table hr.emp purge;
create table hr.emp
as
select employee_id, last_name||' '|| first_name name, salary*12 sal
from hr.employees;
select * from hr.emp;
ex 3)
drop table hr.emp purge;
create table hr.emp
as
select *
from hr.employees
where 1 = 2; -- 테이블 구조만 복제, 행은 복제 되지 않는다.
select * from hr.emp;
■ insert subquery (데이터 이관 작업 시)
- 테이블에 데이터가 없고 뼈대만 있을 때 이관 작업을 통해 데이터가 다 들어있는 테이블을 만들 수 있다.
- 추출(select밖에 못함)과 입력(insert)을 한다.
- ETL 업무이기도 하다.
ex 1)
insert into hr.emp
select * from hr.employees;
select * from hr.emp;
commit;
▶ 뼈대만 있었던 emp 테이블에 hr.employees 테이블에 있는 데이터들이 이관된 걸 볼 수 있다.
ex 2)
create table hr.test
as
select employee_id, last_name, salary, department_id
from hr.employees
where department_id in(10,20,30);
desc hr.test; -- 출력 1
select * from hr.test; - -출력 2

▶ employees테이블에 있는 사원ID가 10,20,30 인 사원들의 employee_id, last_name, salary, department_id 뽑아서 hr.test 테이블에 복제하는 작업을 한 것이다.
ex 4) 50번 사원도 넣고 싶을 경우
insert into hr.test
select employee_id, last_name, salary, department_id
from hr.employees
where department_id = 50;
▶ 꼭 타입이 같아야 한다.
# rollback을 했을 경우
rollback;
select * from hr.test;
▶ department_id가 10,20,30인 데이터만 남게 된다.
ex 5) 열 별칭을 이용해서 테이블을 만들 경우
drop table hr.test purge;
create table hr.test
as
select employee_id id, last_name name, salary sal, department_id dept_id
from hr.employees
where department_id in(10,20,30);
select * from hr.test;
▶ 열 별칭을 이용해서 이관 작업을 할 수도 있다.
ex 6)
insert into hr.test(id, sal, dept_id)
select employee_id, salary, department_id
from hr.employees
where department_id = 40;
▶ 오류가 뜨는 경우이다.
▶ 테이블 구조를 확인해 보면
desc hr.test;
▶ 제약 조건을 보면 name에 NOT NULL 조건이 있다. 이 말은 즉 insert를 할 때 꼭 넣어줘어야 한다. 하지만 name 데이터가 빠졌기 때문에 오류가 난 것이다.
# 출력을 하고 싶을 경우
insert into hr.test(id, name, sal)
as
select employee_id, last_name, salary
from hr.employees
where department_id = 40;
rollback;
▶ 결과는 나오지만 department_id가 40인 사원의 값이 null이 나온 걸 볼 수 있다. 그 이유는 위에서 CTAS 할 때 40인 값은 CTAS를 안 해줬기 때문에 null이 나온다.
select * from user_users;
select * from user_sys_privs; -- 내가 받은 시스템 권한 확인하는 법
select * from role_sys_privs; -- 내가 받은 role 권한 확인
select * from session_privs; -- 위에 2개를 한꺼번에 보고 싶을 때
select * from user_ts_quotas; -- user session 후 자신의 정보를 확인하고 싶을 경우
create table hr.mgr(
id number(3),
name varchar2(30),
day date)
tablespace users;
select * from hr.mgr;
▶ 아직 insert문에 데이터를 안 넣어줬기 때문에 비어있는 값이 나오는 것이다.
# 주의할 것
create table hr.test
tablespace users
as
select employee_id, last_name, salary, department_id
from hr.employees
where department_id in(10,20,30);▶ 꼭 CTAS를 이용할 때 create문 밑에 tablespace users를 쓰는 습관을 가지는 게 좋다.
문제) employees 테이블에 있는 관리자 사원들의 employee_id, last_name, hire_date를 mgr 테이블에 데이터 이행작업을 수행하세요.
insert into hr.mgr
select employee_id, last_name, hire_date
from hr.employees e
where exists(select 'x'
from hr.employees
where manager_id = e.employee_id);
select * from hr.mgr;
commit;
▶ hr.employees 테이블 안에 employee_id와 관리자 사원 id가 포함하면 employee_id, last_name, hire_date를 출력해 준다.
select * from hr.emp;
drop table hr.emp;▶ 위부터 차례대로 실행하면 emp 테이블은 아까 CTAS 작업을 통해 employees 테이블의 복제가 되어있다. 하지만 drop을 통해 테이블을 삭제한 후 다시 emp 테이블을 조회해 보면

▶테이블이 존재하지 않다는 오류가 나온다.
# 다시 emp 테이블 생성
create table hr.emp(
id number(3),
name varchar2(60),
dept_id number,
dept_name varchar2(30))
tablespace users;
desc hr.emp;

※ 이름, 주소 등의 길이가 변할 수 있는 값은 VARCHAR를 사용하는 것이 좋고,
사번, 주민등록번호와 같이 길이가 일정한 데이터는 CHAR를 사용하는 게 좋다.
# emp 테이블 이관 작업
insert into hr.emp(id, name)
select employee_id, last_name||' '||first_name
from hr.employees;
select * from hr.emp;
commit;
▶ employees에 테이블에 있는 employee_id, name을 가져오는데 name을 가져올 때 last_name과 first_name 사이에 공백을 둬서 데이터를 가져오고 emp에 CTAS 작업을 하는 SQL문이다.
▶ dept_id, dept_name에 null이 나오는 이유는 CTAS 작업 시 값을 넣어주지 않았기 때문이다.
# 특정 데이터만 보고 싶을 경우
select * from hr.emp where id = 100;
■ update subquery
ex 1) 기존 방식
- 100번 사원을 null값으로 바꿀 때
update hr.emp
set name = null
where id = 100;
commit;
select * from hr.emp;
# update subquery 이용
update hr.emp
set name = (select last_name||' '||first_name
from hr.employees
where employee_id = 100)
where id = 100;
ex 2)
select department_id
from hr.employees
where department_id = 100;
update hr.emp
set dept_id = 90
where id = 100;▶ department_id가 100인 사원을 뽑게 되면 여러 명이 나올 것이다.
▶ 밑에 처럼 update문을 통해 dept_id를 다 입력해줘야 한다면 100인 사원의 로우 수만큼 update문을 써줘야 하는 번거로움이 있다.
▶ 그래서 update subquery를 통해 간편하게 해결할 수 있다.
update hr.emp e
set dept_id = (select department_id
from hr.employees
where employee_id = e.id);
select * from hr.emp;
commit;
▶ 사원들의 department_id에 값이 들어간 걸 볼 수 있다.
ex)
update hr.emp e
set dept_name = (select department_name
from hr.departments
where department_id = e.dept_id);
select * from hr.emp;
commit;▶ 현재 데이터에 department_name은 값을 안 줬기 때문에 다 null로 되어있다.
▶ 하지만 update subquery를 통해 emp테이블과 department 테이블의 id로 연결해서 department_name을 넣어주는 방식이다.

■ delete subquery
delete from hr.emp
where id in(select employee_id
from hr.employees
where last_name like 'k%');
select * from hr.emp;
rollback;▶ 먼저 employees 테이블에 있는 last_name이 k로 시작하는 employee_id를 다 추출한 것이 emp테이블 id와 일치한 것만 삭제하는 SQL문이다.

▶ 일치한 데이터의 행이 삭제된다.
# job_id를 한 번이라도 바꾼 사람을 삭제하고 싶은 경우
- correlated subquery를 이용한 delete문
select *
from hr.emp e
where exists(select 'x'
from hr.job_history
where employee_id = e.id);
delete from hr.emp e
where exists(select 'x'
from hr.job_history
where employee_id = e.id);
rollback;

■ 다중 테이블 INSERT (9i)
- source 테이블에서 데이터를 추출해서 여러 개의 target 테이블에 데이터로 로드(insert)하는 SQL문
- ETL (Extraction(추출), Trasnsformation(변형), Loding(적재))
1. 무조건 insert all
- 기존방식은 source에서 terget 쪽으로 부어내면서 수행하는데 이 과정에서 테이블을 최소 2번 이상 엑세스하기 때문에 성능적으로 좋지 않기 때문에 사용한다.
- 모든 정보를 뽑고 싶을 땐 from절엔 *을 쓸 수 있지만 values()절에는 * 쓸 수 없고 뽑고 싶은 컬럼을 다 적어줘야 한다.
ex) 기존 방식
# sal_history 테이블 생성
create table hr.sal_history
tablespace users
as
select employee_id, hire_date, salary
from hr.employees
where 1 = 2;
select * from hr.sal_history;
-----------------------------
# mgr_history 테이블 생성
create table hr.mgr_history
tablespace users
as
select employee_id, manager_id, salary
from hr.employees
where 1 = 2;
select * from hr.mgr_history;
rollback;

▶하지만 이 방법은 좋지 않다. 그 이유는 동일한 코드로 이관 작업을 하게 되면 같은 테이블을 2번 엑세스하기 때문에 성능적으로 안 좋다.
# 성능 개선 방법 (insert all 이용)
insert all
into hr.sal_history(employee_id, hire_date, salary) values(id, day, sal)
into hr.mgr_history(employee_id, manager_id, salary) values(id, mgr, sal)
select employee_id id, hire_date day, manager_id mgr, salary * 1.1 sal
from hr.employees;
select * from hr.mgr_history;
select * from hr.sal_history;
rollback;

■ 조건 insert all
- 한 조건이 참이어도 뒤에 조건을 체크하고 참이면 데이터가 참인 테이블에 다 들어간다.
create table hr.emp_history(id number, day date, sal number)
tablespace useres;
create table hr.emp_sal(id number, comm number(5,2), sal number)
tablespace users;insert all
when day < to_date('2005-01-01', 'yyyy-mm-dd') and sal >= 5000
into hr.emp_history(id, day, sal) values(id, day, sal)
when comm is not null then
into hr.emp_sal(id, comm, sal) values(id, comm, sal)
select employee_id id, hire_date day, salary sal, commission_pct comm
from hr.employees;▶ insert all은 첫 번째 조건이 참이여도 다음 조건을 체크한다. 그래서 다음 조건도 참이면 참인 테이블에 데이터가 다 들어간다고 보면 된다.
▶ 예를 들어 입사한 날짜가 2003년도이고 commission을 받고 있다면 둘 다 참이기 때문에 2 테이블에 데이터가 들어간다.
select * from hr.emp_history;
select * from hr.emp_sal;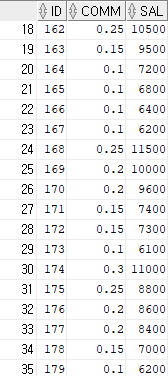
■ 조건 first insert
- 하나라도 조건이 참이면 뒤에 조건은 체크 안 하고 데이터가 들어가고 넘어간다.
ex) 3개의 테이블 생성
create table hr.sal_low(id number, name varchar2(30), sal number)
tablespace users;
create table hr.sal_mid(id number, name varchar2(30), sal number)
tablespace users;
create table hr.sal_high(id number, name varchar2(30), sal number)
tablespace users;
ex) first insert 이용
insert first
when sal < 5000 then
into hr.sal_low(id, name, sal) values(id, name, sal)
when sal between 5000 and 10000 then
into hr.sal_mid(id, name, sal) values(id, name, sal)
else
into hr.sal_high(id, name, sal) values(id, name, sal)
select employee_id id, last_name name, salary sal
from hr.employees;
rollback;▶ employees 테이블의 salary 값이 5000 이하이면 sal_low 테이블에 id, name, sal 해당 사원의 정보를 넣어준다.
select * from hr.sal_low;
select * from hr.sal_mid;
select * from hr.sal_high;
▶ 출력 1~3 더하면 107개 잘 나오는 걸 볼 수 있다.
ex)
create table hr.oltp_emp
tablespace users
as
select employee_id, last_name, salary, department_id
from hr.employees;
create table hr.dw_emp
tablespace users
as
select employee_id, last_name, salary, department_id
from hr.employees
where department_id = 20;select * from hr.oltp_emp;
select * from hr.dw_emp;
# 기존 테이블의 컬럼을 추가하는 방법
1) 일단 테이블의 구조 확인
desc hr.oltp_emp;
2) flag라는 컬럼을 추가
alter table hr.oltp_emp where flag char(1);
3) 컬럼이 잘 들어갔는지 테이블 구조 다시 확인
desc hr.oltp_emp;
4) 테이블을 조회해 보면
select * from hr.oltp_emp;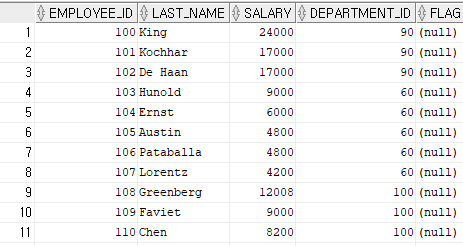
▶ 보면 flag라는 컬럼이 추가가 되었고, 아직 값을 넣지 않았기 때문에 다 null이 나온다.
ex)
select * from hr.oltp_emp where employee_id in (201,202);
select * from hr.dw_emp where employee_id in (201,202);
update hr.oltp_emp
set flag = 'd'
where employee_id = 202;
update hr.oltp_emp
set salary = 20000
where employee_id = 201;
commit;▶ oltp_emp 테이블에 사원ID가 202번인 사원은 flag 값을 d로 바꿔준다.
▶ oltp_emp 테이블에 사원ID가 201번 사원의 salary값을 20000으로 바꿔준다.

문제 1) oltp_emp에 있는 사원들 중에 dw_emp에 존재하는 사원 정보를 출력해 주세요.
select *
from hr.oltp_emp o
where exists(select 'x'
from hr.dw_emp
where employee_id = o.employee_id);
문제 2) dw_emp에 있는 사원들 중에 oltp_emp에 존재하는 사원들의 급여를 oltp_emp에 급여를 기준으로 10% 인상해 주세요.
select *
from hr.dw_emp d
where exists (select 'x'
from hr.oltp_emp
where employee_id = d.employee_id);
▶ 인상 전 값이다
# 10% 인상 후
update hr.dw_emp d
set salary = (select salary * 1.1
from hr.oltp_emp
where employee_id = d.employee_id);
rollback;
▶ 밑에 걸 실행하고 위에 걸 다시 조회하면 급여가 10프로 인상된 값이 나온다.
문제 3) dw_emp에 있는 사원 중에 oltp_emp에 존재하고 flag가 'd'인 사원의 정보를 출력해 주세요.
select *
from hr.dw_emp d
where exists(select 'x'
from hr.oltp_emp
where employee_id = d.employee_id
and flag = 'd');
문제 4) oltp_emp에 있는 데이터 중에 dw_emp에 없는 데이터를 dw_emp에 입력해 주세요.
1. oltp_emp에 있는 데이터 중에 dw_emp에 없는 데이터를 먼저 뽑는다.
select *
from hr.oltp_emp o
where not exists(select 'x'
from hr.dw_emp
where employee_id = o.employee_id);
▶ 2개를 제외한 105개가 출력이 된다.
insert into hr.dw_emp(employee_id, last_name, salary, department_id)
select employee_id, last_name, salary, department_id
from hr.oltp_emp o
where not exists(select 'x'
from hr.dw_emp
where employee_id = o.employee_id);
rollback;
■ merge
- insert, update, delete문을 한꺼번에 수행하는 SQL문
- 성능 관점으로도 좋다.
ex)
select * from hr.dw_emp; -- target table (실제 update, delete, insert가 되는 곳)
select * from hr.oltp_emp; -- source tablemerge into hr.dw_emp d
using hr.oltp_emp o -- 원하는 결과를 조회하는 곳
on (d.employee_id = o.employee_id) -- 조인조건 술어 (존재여부)
when matched then -- 키 값이 일치가 되면
update set
d.salary = o.salary * 1.1
delete where o.flag = 'd'
when not matched then
insert(d.employee_id, d.last_name, d.salary, d.department_id)
values(o.employee_id, o.last_name, o.salary, o.department_id);▶ merge도 마찬가지로 트랜젝션이 발생하기 때문에 항상 마지막에 commit 할지 rollback 할지 써줘야 한다.
'oracle SQL' 카테고리의 다른 글
| 2024.12.17 14일차 수업 (0) | 2024.12.17 |
|---|---|
| 2024.12.16 13일차 수업 (0) | 2024.12.16 |
| 2024.12.11 11일차 수업 (0) | 2024.12.11 |
| 2024.12.10 10일차 수업 (2) | 2024.12.10 |
| 2024.12.09 9일차 수업 (2) | 2024.12.09 |



