# CTAS 복제 복습
create table hr.emp_copy
tablespace users
as select * from hr.employees;desc hr.emp_copy;
# 소유자 관점(만든 사람) 테이블 정보 확인
select * from user_tables where table_name = 'EMP_COPY';
# DBA 관점에서 테이블 정보 확인
select * from dba_tables where owner = 'HR' and table_name = 'EMP_COPY';
# 소유자 관점 컬럼 정보 확인
select * from user_tab_columns where table_name = 'EMP_COPY';
# DBA 관점에서 컬럼 정보 확인 (dba)
select * from dba_tab_columns where owner = 'HR' and table_name = 'EMP_COPY';
# 컬럼을 추가하는 방법 (hr)
alter table hr.emp_copy add department_name varchar2(30);
select * from user_tab_columns where table_name = 'EMP_COPY';
문제) emp_copy 테이블에 department_name은 값이 없어서 null로 되어있다. departments테이블에 department_name을 가져오고 싶을 때 어떡해야 할까?
1) correlated subquery를 이용한 update문
update hr.emp_copy e
set department_name = (select department_name
from hr.departments
where department_id = e.department_id);
2) merge문
merge into hr.emp_copy e --target table (실제 업데이트가 되는 곳)
using hr.departments d --source table
on (e.department_id = d.department_id)
when matched then
update set e.department_name = d.department_name;
# merge문에도 서브쿼리를 쓸 수 있다.
- using절에 쓸 수 있고 꼭 괄호로 묶어줘야 한다.
merge into hr.emp_copy e
using (select department_id, department_name
from hr.departments) d
on (e.department_id = d.department_id)
when matched then
update set e.department_name = d.department_name;
rollback;
1. 컬럼 타입, 크기를 수정
# 수정 전
desc hr.emp_copy;
select * from user_tab_columns where table_name = 'EMP_COPY';
select * from user_tab_columns where table_name = 'EMP_COPY';
# job_id의 크기를 바꾸고 싶을 경우
alter table hr.emp_copy modify job_id varchar2(20);
select * from user_tab_columns where table_name = 'EMP_COPY';
# job_id 길이 확인
select job_id, length(job_id) from hr.emp_copy;
alter table hr.emp_copy modify job_id varchar2(5);
▶ 오류 뜨는 이유는 현재 값이 들어있는 상태에서 5바이트 보다 큰 값이 들어있기 때문에 오류가 나온다.
alter table hr.emp_copy modify job_id number(20);
▶ 이미 문자로 데이터값이 들어가 있기 때문에 오류가 나온다.
2. 컬럼 삭제
alter table hr.emp_copy drop column job_id; -- alter는 자동 커밋이 되기때문에 주의해야 한다.
select * from user_tab_columns where table_name = 'EMP_COPY';
▶ job_id가 삭제된 걸 볼 수 있다.
■ 제약 조건
- 데이터의 대한 규칙을 만든다.
- 데이터의 대한 품질을 향상하기 위해서 만든다. (궁극적인 목표)
1. primary key
- 테이블의 대표키(기본키)
- unique(유일한 값), null값은 허용할 수 없다. (NOT NULL)
- 테이블당 무조건 하나 생성
- 자동으로 unique index 생성
# 제약조건 정보 확인 (소유자)
select * from user_constraints where table_name = 'EMPLOYEES'; -- 출력 1
select * from user_cons_columns where table_name = 'EMPLOYEES'; -- 출력 2

# 제약조건 정보 확인 (DBA)
select * from dba_constraints where owner = 'HR' and table_name = 'EMPLOYEES'; -- 출력 1
select * from dba_cons_columns where owner = 'HR' and table_name = 'EMPLOYEES'; -- 출력 2

# primary key 제약조건 추가
- 고유 이름으로 제약조건을 걸어야 한다.
alter table hr.emp_copy add constraint emp_id_pk primary key(employee_id);
# index 정보 확인
select * from user_indexes where table_name = 'EMP_COPY'; -- 출력 1
select * from user_ind_columns where table_name = 'EMP_COPY'; -- 출력 2
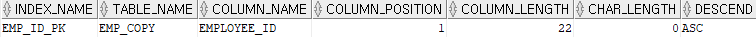
# 제약조건 삭제
alter table hr.emp_copy drop constraint emp_id_pk;select * from user_indexes where table_name = 'EMP_COPY'; -- 출력 1
select * from user_ind_columns where table_name = 'EMP_COPY'; -- 출력 2

# primar key 제약조건 추가
- 제약조건 이름을 생략하게 되면 자동으로 sys_c숫자 형식의 이름으로 생성된다.
- 위에처럼 이름을 줘서 하는 게 좋다.
alter table hr.emp_copy add primary key(employee_id);select * from user_indexes where table_name = 'EMP_COPY'; -- 출력 1
select * from user_ind_columns where table_name = 'EMP_COPY'; -- 출력 2

# 제약조건 삭제 다른 방법
alter table hr.emp_copy drop constraint SYS_C007027;
또는
alter table hr.emp_copy drop primary key;select * from user_indexes where table_name = 'EMP_COPY'; -- 출력 1
select * from user_ind_columns where table_name = 'EMP_COPY'; -- 출력 2

# 샘플 테이블 삭제
drop table hr.emp_copy purge;
drop table hr.emp purge;
drop table hr.dept purge;
# 테이블 생성
create table hr.emp(id number, name varchar2(30), day date)
tablespace users;
## 사원ID도 같고 고유값에 null이 들어가면 성능적으로 안 좋다.
insert into hr.emp(id, name, day)
values(1, 'sql', sysdate);
insert into hr.emp(id, name, day)
values(1, 'psql', sysdate);
insert into hr.emp(id, name, day)
values(null, 'itwill', sysdate);
select * from hr.emp;
rollback;
## primary key 추가
alter table hr.emp add constraint emp_id_pk primary key(id);insert into hr.emp(id, name, day)
values(1, 'sql', sysdate);
insert into hr.emp(id, name, day)
values(1, 'psql', sysdate);
-> 다시 실행하면 오류 뜬다. 이유는 primary key로 제약조건을 걸었기 때문이다.
insert into hr.emp(id, name, day)
values(null, 'itwill', sysdate);
-> 다시 실행하면 오류 뜬다. 이유는 primary key로 제약조건을 걸었기 때문이다.select * from hr.emp;
rollback;
▶ pk값으로 id를 지정했는데 같은 id가 또 들어오면 에러를 발생하고, pk값에는 null이 허용되지 않기 때문에 null을 입력하면 에러가 뜬다.
# 테이블 생성 (PK 추가, 데이터 추가)
create table hr.dept(dept_id number, dept_name varchar2(30))
tablespace users;
alter table hr.dept add constraint dept_pk primary key(dept_id);select * from user_constraints where table_name = 'DEPT'; -- 출력 1
select * from user_cons_columns where table_name = 'DEPT'; -- 출력 2
select * from user_indexes where table_name = 'DEPT'; -- 출력 3
select * from user_ind_columns where table_name = 'DEPT'; -- 출력 4



## 데이터 값 넣기
insert into hr.dept(dept_id, dept_name) values(10,'총무팀');
insert into hr.dept(dept_id, dept_name) values(20,'인사팀');
commit;
select * from hr.dept;
desc hr.emp; -- 출력 1
alter table hr.emp add dept_id number;
desc hr.emp; -- 출력 2

ex)
insert into hr.emp(id, name, day, dept_id) values(1,'홍길동', sysdate, 10);
insert into hr.emp(id, name, day, dept_id) values(2,'박찬호', sysdate, 30); -- 없는 부서 코드
commit;
select * from hr.emp;
ex) outer join
select e.*, d.*
from hr.emp e, hr.dept d
where e.dept_id = d.dept_id(+); -- 출력 1
delete from hr.emp;
commit;
select * from hr.emp; -- 출력 2

■ foreign key
- 외래키, 참조 무결성 제약조건이라고 함
- 동일한 테이블이나 다른 테이블의 primary key, unique key 제약조건만 참조한다.
- 데이터 품질때문에 한다.
- 중복값 허용, null값 허용
select * from user_constraints where table_name in ('EMP','DEPT'); -- 출력 1
select * from user_cons_columns where table_name in ('EMP','DEPT'); -- 출력 2
select * from user_indexes where table_name in ('EMP','DEPT'); -- 출력 3
select * from user_ind_columns where table_name in ('EMP','DEPT'); -- 출력 4



# foreign key 추가
alter table hr.emp add constraint emp_dept_id_fk foreign key(dept_id)
references hr.dept(dept_id);select * from user_constraints where table_name in ('EMP','DEPT'); -- 출력 1
select * from user_cons_columns where table_name in ('EMP','DEPT'); -- 출력 2
select * from user_indexes where table_name in ('EMP','DEPT'); -- 출력 3
select * from user_ind_columns where table_name in ('EMP','DEPT'); -- 출력 4



## 데이터값 추가
insert into hr.emp(id, name, day, dept_id) values(1,'홍길동', sysdate, 10);
insert into hr.emp(id, name, day, dept_id) values(2,'박찬호', sysdate, 30); -- 오류나옴
-> pk에 없는 값이 입력됐기 때문이다.
select * from hr.emp;
commit;

insert into hr.emp(id, name, day, dept_id) values(2,'박찬호', sysdate, null);
commit;
select * from hr.emp;
▶ null은 허용되기 때문에 출력이 된다.
# 테이블 조회
select * from hr.emp;
select * from hr.dept;delete from hr.dept where dept_id = 10;▶ 오류 발생한다. 이유는 foreign key 제약조건이 걸려 있으면서 10번 부서에 해당하는 사원정보가 존재하기 때문에 삭제가 오류 발생한다.
delete from hr.dept where dept_id = 20;▶ 수행이 된다. 이유는 20번 부서에 해당하는 사원정보가 존재하지 않기 때문에 삭제가 수행된다.
select * from user_constraints where table_name in ('EMP','DEPT');
alter table hr.dept drop primary key;
또는
alter table hr.dept drop constraint dept_pk;▶ 삭제가 안 된다. primary key 제약조건을 삭제하려고 하는 순간 foreign key 제약조건이 걸려 있으면 foreign key 제약조건을 먼저 삭제한 후 primary key 제약조건을 삭제하면 된다.
# 해결방법
1) foreign key 제약조건 삭제
alter table hr.emp drop constraint emp_dept_id_fk;2) primary key 제약조건 삭제
alter table hr.dept drop constraint primary key;
## 해결방법 2 - 훨씬 간편함
alter table hr.dept drop primary key cascade;
select * from user_constraints where table_name in ('EMP','DEPT');▶ cascade (옵션) : 나를 참조하는 제약조건을 삭제하고, primary key 제약조건을 삭제

3. unique 제약조건
- 유일한 값만 체크
- null 허용한다.
- 자동으로 unique index 생성
select * from user_constraints where table_name in ('EMP','DEPT'); -- 출력 1
select * from user_cons_columns where table_name in ('EMP','DEPT'); -- 출력 2# unique 제약조건 걸기
select * from hr.dept;
alter table hr.dept add constraint dept_name_uk unique(dept_name);

# 데이터 추가
insert into hr.dept(dept_id, dept_name) values(30,'총무팀');
▶ 오류 발생이유는 dept_name에 unique 제약조건이 생성되어 있어서 중복되는 값은 입력될 수 없다.
insert into hr.dept(dept_id, dept_name) values(30, null);▶ null은 허용이기 때문에 출력이 된다.

update hr.dept
set dept_name = '인사팀'
where dept_id = 30;▶ 오류 발생한다. 중복되는 값은 무조건 에러 뜬다.

# unique 제약조건 삭제하는 방법 (시험에도 많이 나옴)
select * from user_constraints where table_name in ('EMP','DEPT');
1)
alter table hr.dept drop constraint dept_name_uk;
2)
alter table hr.dept drop unique(dept_name);▶ 마지막에 dept_name 컬럼을 꼭 입력해줘야 한다.
select * from user_constraints where table_name in ('EMP','DEPT');
▶ uk가 삭제된 걸 볼 수 있다.
4. check 제약조건
- 조건값이 true인 경우 insert, update할 수 있도록 만드는 제약조건
- null 허용, 중복값 허용한다.
desc hr.emp; -- 출력 1
alter table hr.emp add sal number;
desc hr.emp; -- 출력 2

alter table hr.emp add constraint emp_sal_ck check(sal >= 1000 and sal <= 2000);
select * from user_constraints where table_name in ('EMP','DEPT');

▶ 조건식에 between을 써도 가능하다.
# 데이터 추가
insert into hr.emp(id, name, day, dept_id, sal)
values(3, '손흥민', sysdate, 20, 1500);
select * from hr.emp;
commit;
# 에러 발생
insert into hr.emp(id, name, day, dept_id, sal)
values(4, '이문세', sysdate, 10, 500);
▶ check 제약조건에 위반되었기 때문에 오류 발생
# null
insert into hr.emp(id, name, day, dept_id, sal)
values(4, '이문세', sysdate, 10, null);
commit;
select * from hr.emp;
# 에러
update hr.emp
set sal = 3000
where id = 4;▶ check 제약조건에 위반되었기 때문에 오류 발생
# 출력
update hr.emp
set sal = 1500
where id = 4;
# check 제약조건 삭제
alter table hr.emp drop constraint emp_sal_ck;
select * from user_constraints where table_name in ('EMP','DEPT');
5. NOT NULL 제약조건
- null값을 허용할 수 없는 제약조건
- 중복 허용한다.
select * from user_constraints where table_name in ('EMP','DEPT'); --출력 1
desc hr.emp; -- 출력 2

▶ 출력 2 : NOT NULL이라고 보여지지만 내부적으론 PK이기 때문에 CTAS 때 복제가 안 된다.
insert into hr.emp(id, name, day, dept_id, sal)
values(5, null, sysdate, 10, 1000);
▶ 이름이 null일 순 없으므로 무조건 값을 입력해줘야 한다.
rollback;
alter table hr.emp add constraint emp_name_nn not null(name); --기존 추가방식
▶ 유효한 식별자가 아니기 때문에 오류 뜬다.
# 제약조건 추가 방법 (NOT NULL) - modify 이용
alter table hr.emp modify name constraint emp_name_nn not null;
select * from user_constraints where table_name in ('EMP','DEPT');
# 오류 1
insert into hr.emp(id, name, day, dept_id, sal)
values(5, null, sysdate, 10, 1000);▶ 위에서 넣었던 코드를 다시 입력하면 오류 뜬다. 이유는 NOT NULL 제약조건이 걸려있을 땐 null을 허용할 수 없기 때문이다.
ex) 오류 2
update hr.emp
set name = null
where id = 1;
desc hr.emp;
# NOT NULL 제약조건 삭제
select * from user_constraints where table_name in ('EMP','DEPT'); -- 출력 1
alter table hr.emp drop constraint emp_name_nn;
또는
alter table hr.emp modify name null;
select * from user_constraints where table_name in ('EMP','DEPT'); -- 출력 2

# 테이블 삭제
drop table hr.emp purge;
drop table hr.dept purge;
# 테이블 생성
create table hr.dept(
dept_id number constraint dept_id_pk primary key,
dept_name varchar2(30) constraint dept_name_uk unique)
tablespace users;
select * from user_constraints where table_name in ('EMPLOYEES','DEPARTNEBTS');
▶ 에러 나오는 이유는 동일한 제약조건 이름이 있기 때문에 오류가 뜬다.
★ 제약조건 이름은 유저 레벨에서 고유한 이름으로 생성해야 한다.
# 해결방법
create table hr.dept(
dept_id number constraint dept_pk primary key,
dept_name varchar2(30) constraint dept_name_uk unique)
tablespace users;
# 테이블 삭제 후 다시 생성
create table hr.dept(
dept_id number primary key,
dept_name varchar2(30) unique)
tablespace users;
select * from user_constraints where table_name in ('EMP','DEPT');
▶constraint를 안 적고 실행하면 매우 불편하고 현장에선 거의 안 쓰기 때문에 이름을 표현하는 습관을 가지자
# emp 테이블 생성
create table hr.emp(
id number constraint emp_id_pk primary key,
name varchar2(30) constraint emp_name_nn not null,
sal number,
dept_id number constraint emp_dept_id_fk references hr.dept(dept_id),
constraint emp_name_uk unique(name),
constraint emp_sal_ck check(sal between 1000 and 2000))
tablespace users;
select * from user_constraints where table_name in ('EMP','DEPT');
▶ 컬럼을 정의하면서 제약조건을 만드는 형식을 열 레벨 정의라고 표현하고, 열 정의를 다하고 나서 constraint 하는 걸 테이블 레벨 정의라고 한다. 편한 걸로 하면 된다.
▶ not null 제약조건은 열 레벨 정의로만 해야 한다!
create table hr.emp(
id number,
name varchar2(30) constraint emp_name_nn not null, -- 열 레벨 정의
sal number,
dept_id number,
constraint emp_id_pk primary key(id), -- 테이블 레벨 정의
constraint emp_name_uk unique(name),
constraint emp_sal_ck check(sal between 1000 and 2000),
constraint emp_dept_id_fk foreign key(dept_id) references
hr.dept(dept_id))
tablespace users;▶ 테이블 레벨 정의할 때는 마지막에 컬럼명을 꼭 적어줘야 한다.
▶ 제약조건을 꼭 하나만 걸 수 있는 것은 아니다. 위에 보면 unique 제약조건에도 컬럼에 name이 들어가고, not null 제약조건에도 name이 들어가도 실행이 된다.
▶ 테이블을 생성할 때 2가지 방법으로 생성할 수 있다. (열 레벨 정의, 테이블 레벨 정의) -> 둘 중에 편한 거 쓰면 되지만 NOT NULL 제약조건은 무조건 열 레벨로 해야 한다.
▶ 열 레벨 정의할 때 foreign key를 꼭 쓰지 말고 바로 references 써야 하지만, 테이블 레벨 정의할 때는 foreign key(컬럼)을 써줘야 한다.
▶ 만약 not null 조건과 unique 조건을 합쳐서 만들고 싶을 때
create table hr.emp(
id number,
name varchar2(30)
constraint emp_name_nn not null
constraint emp_name_uk unique, -- 열 레벨 정의
sal number,
dept_id number,
constraint emp_id_pk primary key(id), -- 테이블 레벨 정의
constraint emp_sal_ck check(sal between 1000 and 2000),
constraint emp_dept_id_fk foreign key(dept_id) references
hr.dept(dept_id))
tablespace users;
drop table hr.dept purge;
▶ 나를 참조하고 있는 제약조건(foreign key)이 있기 때문에 삭제 오류 발생
# 삭제하고 싶을 경우
1) 나를 참조하고 있는 제약조건을 먼저 삭제한다.
drop table hr.dept cascade constraint purge;
select * from user_constraints where table_name in ('EMP','DEPT');▶ cascade constraint : 나를 참조하고 있는 제약조건(foreign key)을 먼저 삭제한다.

drop table hr.emp cascade constraint purge;
select * from user_constraints where table_name in ('EMP','DEPT');
# 테이블 다시 생성
create table hr.dept(
dept_id number constraint dept_pk primary key,
dept_name varchar2(30) constraint dept_name_uk unique)
tablespace users;
create table hr.emp(
id number,
name varchar2(30) constraint emp_name_nn not null,
sal number,
dept_id number,
constraint emp_id_pk primary key(id),
constraint emp_sal_ck check(sal between 0 and 30000),
constraint emp_dept_id_fk foreign key(dept_id) references hr.dept(dept_id))
tablespace users;
■ 테이블 이름 수정
ex) 만약 emp 테이블을 잘못 만들었을 경우 (데이터도 있다고 가정)
select * from hr.emp;
select * from hr.dept;
desc hr.emp;
insert into hr.dept(dept_id, dept_name)
select department_id, department_name
from hr.departments;
commit;
insert into hr.emp(id, name, sal, dept_id)
select employee_id, last_name, salary, department_id
from hr.employees;
commit;
# 제약조건 확인
select * from user_constraints where table_name in ('EMP','DEPT');
select * from user_cons_columns where table_name in ('EMP','DEPT');
select * from user_indexes where table_name in ('EMP','DEPT');
select * from user_ind_columns where table_name in ('EMP','DEPT');
# 테이블 이름 수정 (소유자를 적으면 에러 뜬다!)
- rename 옛날 테이블 이름 to 새로운 테이블 이름;
- rename만큼은 소유자 이름으로 접속해야 한다.
rename emp to emp_new;select * from hr.emp;
select * from hr.emp_new;
# 제약조건 확인할 때
select * from user_constraints where table_name in ('EMP_NEW','DEPT');
select * from user_cons_columns where table_name in ('EMP_NEW','DEPT');
select * from user_indexes where table_name in ('EMP_NEW','DEPT');
select * from user_ind_columns where table_name in ('EMP_NEW','DEPT');
# 테이블 수정하는 방법 2번째
- alter table 옛날 테이블 이름 rename to 새로운 테이블 이름;
alter table emp_new rename to emp;
select * from hr.emp;
select * from user_constraints where table_name in ('EMP','DEPT');
select * from user_cons_columns where table_name in ('EMP','DEPT');
select * from user_indexes where table_name in ('EMP','DEPT');
select * from user_ind_columns where table_name in ('EMP','DEPT');
■ 컬럼 이름 수정
- alter table hr.emp rename column 옛날 컬럼 to 바꿀 컬럼 이름;
desc hr.emp;
# ID 컬럼명을 바꾸고 싶을 경우
alter table hr.emp rename column id to emp_id;
desc hr.emp;
select * from user_constraints where table_name in ('EMP','DEPT');
select * from user_cons_columns where table_name in ('EMP','DEPT');
select * from user_indexes where table_name in ('EMP','DEPT');
select * from user_ind_columns where table_name in ('EMP','DEPT');▶ 업무팀에서 이름 바꿔달라고 요청서가 들어오면 하면 된다.
■ 제약조건 이름 수정
- alter table hr.emp rename constraint 옛날 이름 to 바꿀 이름;
select * from user_constraints where table_name in ('EMP','DEPT');
select * from user_cons_columns where table_name in ('EMP','DEPT');
select * from user_indexes where table_name in ('EMP','DEPT');
select * from user_ind_columns where table_name in ('EMP','DEPT');
ex) EMP_ID_PK 이름을 수정하고 싶을 때
alter table hr.emp rename constraint emp_id_pk to emp_pk;select * from user_constraints where table_name in ('EMP','DEPT');
select * from user_cons_columns where table_name in ('EMP','DEPT');
select * from user_indexes where table_name in ('EMP','DEPT');
select * from user_ind_columns where table_name in ('EMP','DEPT');
■ 인덱스 이름 수정
- alter index 옛날 이름 rename to 바꿀 이름;
select * from user_indexes where table_name in ('EMP','DEPT');
select * from user_ind_columns where table_name in ('EMP','DEPT');
# INDEX_NAME 안에 EMP_ID_PK를 수정하고 싶을 경우
alter index emp_id_pk rename to emp_id_idx;select * from user_indexes where table_name in ('EMP','DEPT');
select * from user_ind_columns where table_name in ('EMP','DEPT');
'oracle SQL' 카테고리의 다른 글
| 2024.12.17 14일차 수업 (0) | 2024.12.17 |
|---|---|
| 2024.12.12 12일차 수업 (2) | 2024.12.12 |
| 2024.12.11 11일차 수업 (0) | 2024.12.11 |
| 2024.12.10 10일차 수업 (2) | 2024.12.10 |
| 2024.12.09 9일차 수업 (2) | 2024.12.09 |



